SMPI status report
Table of Contents
Sitemap
|
|




Here is a small report for my SONGS colleagues about what's up in SMPI since the last "month".
Collective Communications
In the past few weeks Augustin has stabilized all the SMPI collective communication code. This allowed to fix a bunch of bugs (e.g., there was a minimal support for non-contiguous datatypes, which was not working well with the code of some collective operations that tried to make smart optimizations…).
Augustin has taken all the collective communication code from OpenMPI and MPICH and integrated them to SMPI, next to what he already had done for StarMPI! There is still some cleanups to do but it means it is now possible to run with an OpenMPI or an MPICH flavor of SMPI. It may look like a pain to maintain. Yet, Augustin said he could not find much differences from one version to another. For example, in this part of the code, there was just a small decision in one algorithm that changed between OpenMPI 1.5 and OpenMPI 1.7. He also had a brief look at MVAPICH where a lot of work seems to have been done for collective operations (multi-cast collectives, 0-copy collectives, …).
If SMPI provides a decent modeling of network and contention, that means, it should ultimately be possible to compare collective algorithms in a rather fair way and we have now a nice collection.
Also, when looking into the code of OpenMPI, he noticed there is a way to select which implementation of SendRecv should be used…
Anyway, now, he needs to document all this.
Coverage
The side effect #1 of having now a stable version of collective operations is that BigDFT now works very well in SMPI. There are still a few deadlocks some times that he needs to investigate:
- surprisingly, when permanent receive and surf lazy mechanism are activated, some deadlock happens… :(
- there is something rotten with
WaitAll. It looks like communications are started (thanks to the permanent receive) but the waits that were launched beforehand by other process seem to miss some messages…
Augustin also tried to increase the coverage and stumbled upon the SMPI_SHARED_CALL macro which memorizes the result of a function call. It could be interesting and useful but he will have to do 1) a FORTRAN version of it and 2) mix it with the SMPI_SAMPLE_GLOBAL and SMPI_SAMPLE_LOCAL macros (that also need FORTRAN versions). This will speed up his BigDFT experiments…
InfiniBand early results
Augustin tried the point-to-point calibration of IB. As one could expect, it is much more clean and easy to model than TCP. There is only a discontinuity at 12288 where the protocol switches from eager mode to rendez-vous mode. There are only two synchronization modes.
Now regarding saturation, it looks clean and easy at first sight but looking closer reveals weird phenomenon:
Send/Recv: 10 communications in a row with p pairs of senders of receivers.

This is very stable but surprisingly, the last pair of process is always delayed. Let me clarify this. For example, when P0->P36 | P1->P37 | … | P10 -> P46, the first send of P10 takes 5 times more than it should and the 9 remaining ones take a normal time. And if you add P11 -> P47, then P11 is delayed but P10 is fine! We have no clue of what may be happening here since it is not a collective operation. Just a plain MPI_Send/MPI_Recv. Augustin observed a similar issue on both graphene and griffon. Furthermore, note that when the number of pairs increases, then some other processors start suffering from slowdowns but now it is consistent, i.e., when the number of pairs increases, it's always the same nodes which are slowed down. It looks like if some nodes were sharing a link with other nodes…
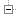
Now, with an increasing number of pairwise SendRecv (i.e., P_0 <-> P_n/2, P1 <-> P_{n/2+1}, …). As usual, each experiment is a series of 10 communications.
Now, there is no delay but a uniform slow down when more than 15 pairs of nodes are involved (you may have to zoom to have a better view). Interestingly, it is always the same nodes which are slowed down, which makes it look as if some nodes were sharing links with other nodes. That would be painful to describe but it seems pretty easy to model.
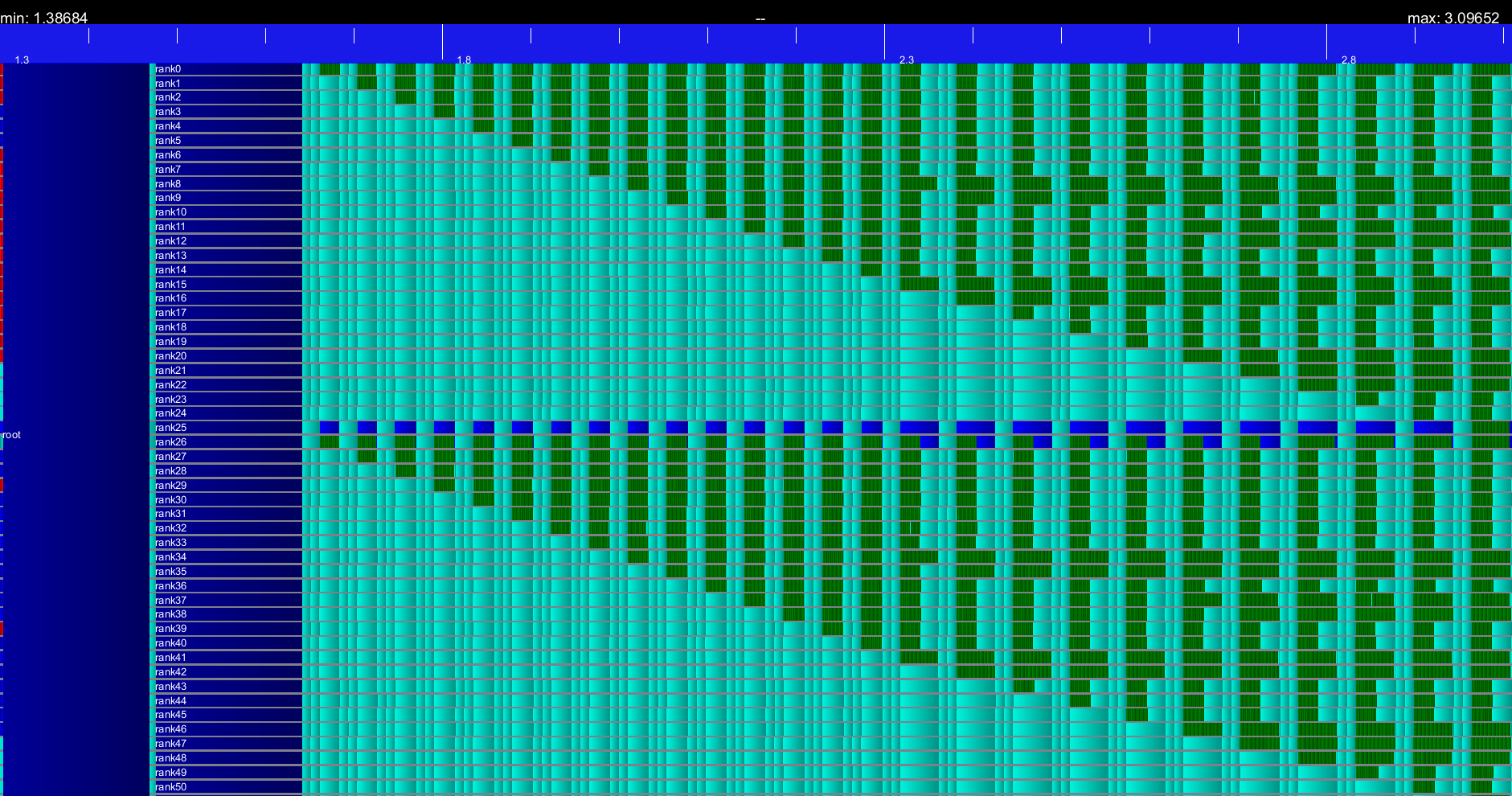
Last but not least, with quadruplets of SendRecv (0->36->1->37->0).
Wow, now there are both delays (of the last group, just like when we had Send/Recv) and somehow uniform slowdowns.
OK, that doesn't look very nice but it does not look like a nightmare either. The real question is what the hell is going on with this delay only on the last group of communicating process ? MPI rank should not have any influence!
Next steps
- Our article will not be accepted at SC'13 but we will rework it and resubmit to PMBS since our goal is to present and advertise for our work and tools.
- The point-to-point experiments should be run within a node (i.e., using shared memory for communications). A little confidence on this will allow us to present experiment results at a larger scale, which is more likely to convince reviewers.
- Augustin would like to look at the impact on computation times of the usage of shared memory communications and having several MPI process on the same node compared to when using only one process per node as we have done so far. He will use BigDFT for this.
- Anne Cécile and Alexandra are making good progress on incorporating energy models in SimGrid. Validation experiments and measurements will be done in the summer and that could be really useful in the context of the Mont-Blanc project.
- The "Incast et RTO" issue. No progress on this side. Augustin will contact Simon Delamare and/or Mathieu Imbert to ask them about this.
Entered on