Toward Better Simulation of MPI Applications on Ethernet/TCP Networks
Sitemap
|
|




Paul Bédaride, Augustin Degomme, Stéphane Genaud, Arnaud Legrand, George S. Markomanolis, Martin Quinson, Mark Stillwell, Frédéric Suter, Brice Videau
This article is an html version of our article published at PMBS/SC'13. All data sets are available at http://figshare.com/articles/SC13_Publication_on_SMPI/833851.
Simulation and modeling for performance prediction and profiling is essential for developing and maintaining HPC code that is expected to scale for next-generation exascale systems, and correctly modeling network behavior is essential for creating realistic simulations. In this article we describe an implementation of a flow-based hybrid network model that accounts for factors such as network topology and contention, which are commonly ignored by other approaches. We focus on large-scale, Ethernet-connected systems, as these currently compose 37.8\% of the TOP500 index, and this share is expected to increase as higher-speed 10 and 100GbE become more available. The European Mont-Blanc project to study exascale computing by developing prototype systems with low-power embedded devices will also use Ethernet-based interconnect. Our model is implemented within SMPI, an open-source MPI implementation that connects real applications to the SimGrid simulation framework. SMPI provides implementations of collective communications based on current versions of both OpenMPI and MPICH. SMPI and SimGrid also provide methods for easing the simulation of large-scale systems, including shadow execution, memory folding, and support for both online and offline (\ie post-mortem) simulation. We validate our proposed model by comparing traces produced by SMPI with those from real world experiments, as well as with those obtained using other established network models. Our study shows that SMPI has a consistently better predictive power than classical LogP-based models for a wide range of scenarios including both established HPC benchmarks and real applications.
1 Introduction
In the High Performance Computing (HPC) field, accurately predicting the execution time of parallel applications is of utmost importance to assess their scalability, and this is particularly true for applications slated for deployment on next-generation exascale systems. While much effort has been put towards understanding the high-level behavior of these applications based on abstract communication primitives, real-world implementations often provide a number of confounding factors that may break basic assumptions and undermine the applicability of these higher level models. For example, implementations of the MPI standard can select different protocols and transmission mechanisms (e.g., eager vs. rendez-vous) depending on message size and network capabilities. Simple delay-based models also do not account for network realities such as network topology and contention. In this work we demonstrate how even relatively minor deviations in low-level implementation can adversely affect the ability of simulations to predict real-world performance, and propose a new network model that extends previous approaches to better account for topology and contention in high-speed TCP networks. We focus on large-scale, Ethernet-connected systems, which currently compose 37.8\% of the TOP500 index\cite{top500}. This share is only expected to increase as higher-speed 10 and 100GbE become more available. The European Mont-Blanc project to study exascale computing by developing prototype systems with low-power embedded devices will also use Ethernet-based interconnect\cite{montblanc}.
Packet-level simulation has long been considered the "gold standard" for modeling network communication, and is available for use in a number of simulation frameworks\cite{mpi-netsim_09,bigsim_04}. However, there are a number of reasons to consider alternatives when simulating parallel applications. First, such applications are likely to generate large amounts of network traffic, and packet-level simulation has high overheads, resulting in simulations that may take significantly longer to run than the corresponding physical experiments. Second, implementing packet-level simulations that accurately model real world behavior requires correctly accounting for a vast array of factors\cite{lucio2003opnet}. In practice, there is little difference between an inaccurate model and an accurate model of the wrong system.
When packet-level simulation becomes too costly or intractable, the most common approach is to resort to simpler delay models that ignore the network complexity. Among these models, the most famous are those of the LogP family\cite{LogP,LogGP,pLogP,LogGPS}. The LogP model was originally proposed by Culler et al.\cite{LogP} as a realistic model of parallel machines for algorithm design. It was claimed as more realistic than more abstract models such as PRAM or BSP. This model captures key characteristics of real communication platforms while remaining amenable to complexity analysis. Unfortunately, while this model may reflect the behavior of specialized HPC networks from the early 1990s, it ignores potentially confounding factors present in modern-day systems.
Flow-based models are a reasonable alternative to both simple analytic models and expensive and difficult-to-instantiate packet-level simulation. In a flow based model, network traffic is treated as a steady state fluid flow through interconnected pipes of varying lengths and sizes (representing delay and bandwidth). Flow-based models are computationally tractable while being able to account for factors such as network heterogeneity. We seek to capture the advantages of a flow-based approach by extending existing validated models of point-to-point communication to better account for network topology and message contention. Recent work suggests that well-tuned flow-based simulation may be able to provide reasonably accurate results for less effort than packet-based simulation, and at much lower cost\cite{Velho_TOMACS13}.
Our model is implemented within SMPI \cite{SMPI}, an open-source MPI implementation that connects real-world applications to the SimGrid\cite{simgrid} simulation framework. With SMPI, standard MPI applications written in C or FORTRAN can be compiled and run in a simulated network environment, and traces documenting computation and communication events can be captured without incurring errors from tracing overheads or improper synchronization of clocks as in physical experiments. SMPI has recently been extended so that the low-level implementations of MPI collective operations more accurately reflect current production versions of both OpenMPI and MPICH. SMPI and SimGrid also provide a number of useful features for simulating applications that may require large amounts of time or system resources to run, including shadow execution, memory folding, and off-line simulation by replay of execution traces\cite{PMBS}. We validate our results by comparing application traces produced by SMPI using our network model with those from real world environments. We also compare with traces obtained using models from the literature.
The specific contributions described in this paper are as follows:
- we propose a new flow-based network model that extends previous LogP-based approaches to better account for network topology and message contention;
- we describe SMPI, the simulation platform, and some useful extensions that we have developed to make this tool more useful to developers and researchers alike (\eg SMPI now implements all the collective algorithms and selection logics of both OpenMPI and MPICH for more faithful comparisons);
- we provide a number of experimental results demonstrating how these extensions improve the ability of SMPI to accurately model the behavior of real-world applications on existing platforms, and also show that competing frameworks using previous models from the literature are unlikely to obtain consistently good results;
- we demonstrate the effectiveness of our proposal by making a thorough study of the validity of our models against hierarchical clusters using TCP over Gigabit Ethernet.
This paper is organized as follows: In Section\ref{sec:models} we discuss essential background information in the area of network modeling. In Section\ref{sec:framework} we describe SMPI, our chosen implementation framework, along with some key features that make it suitable for simulation of large scale systems, and comparisons to competing simulation platforms. In Section\ref{sec:hybrid} we describe our proposed hybrid network model, focusing particularly on how this model captures the complexities of network topology and message contention. In Section\ref{sec:validation} we describe experiments conducted to [in]validate the model, including comparisons of traces from real-world environments as well as traces produced using other network models. In Section\ref{sec:bigdft} we demonstrate the capacity of SMPI to simulate complex MPI applications on a single machine. In Section\ref{sec:related} we discuss related work, including other frameworks for simulating parallel applications and their relevant drawbacks. We conclude in Section\ref{sec:ccl} and also provide a description of proposed areas of future work.
2 Network Modeling Background
\label{sec:models}

Figure 1: The LogGPS model\cite{LogGPS} in a nutshell.
In the LogP model, a parallel machine is abstracted with four parameters: \(L\) is an upper bound on the latency of the network, i.e., the maximum delay incurred when communicating a word between two machines; \(o\) denotes the CPU overhead, i.e., the time that a processor spends processing an emission or a reception and during which it cannot perform any other operation; \(g\) is the gap between messages, whose reciprocal is the processor communication bandwidth; and \(P\) represents the number of processors. Assuming that two processors are ready to communicate, the time to transfer a message of size \(k\) is then \(o+(k-1)\max(g,o)+L+o\). Ideally, these four parameters should be sufficient to design efficient algorithms. Indeed, this model accounts for computation/communication overlap since for short messages, the sender is generally released before the message is actually received. Unfortunately, it fails to accurately model the transmission of long messages that are common in modern parallel applications.
The LogGP model proposed in\cite{LogGP} introduces an additional parameter \(G\) to represent the larger effective bandwidth experienced by long messages. The formula for short messages is unchanged but becomes \(o+(k-1)G+L+o\) for long ones. This simple distinction between short and long messages was extended in\cite{pLogP} with the parameterized LogP model in which \(L\), \(o\), and \(g\) depend on the message size. The rationale is that the overall network performance results from complex interactions between the middleware, the operating system, and the transport and network layers. Hence, performance is generally neither strictly linear nor continuous. This model also introduces a distinction between the sender overhead \(o_s\) and the receiver overhead \(o_r\). However, such models may be difficult to use to design algorithms. For instance, they assume that senders and receivers synchronize and include that synchronization cost in the overhead while some MPI implementations use schemes that may not require synchronization, depending on message size.
Finally, Ino et al. proposed in\cite{LogGPS} the LogGPS model that extends
LogGP by adding two parameters \(s\) and \(S\) to capture the lack of linearity and
the existence of a synchronization threshold. Overheads are represented as
affine functions \(o+kO_s\) where \(O_s\) (resp. \(O_r\)) is the overhead per byte at
the sender (resp. receiver) side. This model is described in
Figure\ref{fig.loggps}, where \(t_s\) (resp. \(t_r\)) is the time at which
MPI_Send (resp. MPI_Recv) is issued. When the message size \(k\) is smaller
than \(S\), messages are sent asynchronously (Figure\ref{fig.loggps.async}).
Otherwise, a rendez-vous protocol is used and the sender is blocked at least
until the receiver is ready to receive the message
(Figure\ref{fig.loggps.sync}). The \(s\) threshold is used to switch from \(g\) to
\(G\), \ie from short to long messages, in the equation. The message transmission
time is thus continuously piece-wise linear in message size
(Figure\ref{fig.loggps.costs}).
To summarize, the main characteristics of the LogGPS model are: the expression of overhead and transmission times as continuous piece-wise linear functions of message size; accounting for partial asynchrony for small messages, i.e., sender and receiver are busy only during the overhead cycle and can overlap communications with computations the rest of the time; a single-port model, i.e., a sequential use of the network card which implies that a processor can only be involved in at most one communication at a time; and no topology support, i.e., contention on the core of the network is ignored as all processors are assumed to be connected through independent bidirectional communication channels. Most of these hypothesis are debatable for many modern computing infrastructures. For example, with multi-core machines, many MPI processes can be mapped to the same node. Furthermore, the increase in the number of processors no longer allows one to assume uniform network communications. Finally, protocol switching typically induces performance modifications on CPU usage similar to those on effective bandwidth, while only the latter are captured by these models.
One alternative to both expensive and difficult-to-instantiate packet-level models and simplistic delay models is flow-level models. These models account for network heterogeneity and have thus been used in simulations of grid, peer-to-peer, and cloud computing systems. Communications, represented by flows, are simulated as single entities rather than as sets of individual packets. The time to transfer a message of size \(S\) between processors \(i\) and \(j\) is then given by \(T_{i,j}(S) = L_{i,j} + S/B_{i,j}\), where \(L_{i,j}\) (resp. \(B_{i,j}\)) is the end-to-end network latency (resp. bandwidth) on the route connecting \(i\) and \(j\). Estimating the bandwidth \(B_{i,j}\) is difficult as it depends on the network topology and on interactions with every other flow. This is generally done by assuming that the flow has reached steady-state, in which case the simulation amounts to solving a bandwidth sharing problem, \ie determining how much bandwidth is allocated to each flow. More formally:
Consider a connected network that consists of a set of links \(\mathcal{L}\), in which each link \(l\) has capacity \(B_l\). Consider a set of flows \(\mathcal{F}\), where each flow is a communication between two network vertices along a given path. Determine a ``realistic'' bandwidth allocation \(\rho_f\) for flow \(f\), such that:
\[\forall l\in\mathcal{L}, \sum_{\text{$f$ \text{going through} $l$}} \rho_f \leq B_l.\]
Many different sharing methods can be used and have been evaluated (for example, in \cite{Velho_TOMACS13}). While such models are rather flexible and account for many non-trivial phenomena (e.g., RTT-unfairness of TCP or cross-traffic interferences)\cite{Velho_TOMACS13}, they ignore protocol oscillations, TCP slow start, and more generally all transient phases between two steady-state operation points as well as very unstable situations. Therefore, they provide generally a very good upper-bound of what can be achieved with a given network, and can serve as a basis on which to build more accurate models.
3 The SMPI Framework
\label{sec:framework}
The goal of our research is to use modeling and simulation to better understand the behavior of real-world large-scale parallel applications, which informs the choice of an appropriate simulation platform. That is, simulations for studying the fine-grain properties of network protocols may have little in common with simulations for studying the scalability of some large-scale parallel computing application. Likewise, models used in algorithm design are expected to be much simpler than those used for performance evaluation purposes. Our choice of SMPI as an implementation environment reflects this goal, as SMPI allows for relatively easy conversion of real-world applications to simulation, and provides a number of useful features for enabling large-scale simulations. SMPI implements about 80% of the MPI 2.0 standard, including most of the network communication related functions, and interfaces directly with the SimGrid simulation toolkit\cite{simgrid}. SimGrid is a versatile tool to study the behavior of large-scale distributed systems such as grids, clouds or peer-to-peer systems. It has been shown to be often much more scalable than ad hoc simulators\cite{DCLV_LSAP_10,simgrid_simix2_12} and to handle simulations with up to two millions of processes\cite{simgrid_simix2_12} without resorting to a parallel machine. In this section we describe SMPI in greater detail, focusing first on its general approach and then later highlighting some of these features.
Full simulation of a distributed application, including CPU and network emulation, induces high overheads, and for many cases it can be even more resource intensive than direct experimentation. This, coupled with the fact that a major goal in many simulations is to study the behavior of large-scale applications on systems that may not be available to researchers, means that there is considerable interest in more efficient approaches. The two most widely applied of these are off-line simulation and partial on-line simulation, both of which are available through SMPI.
In off-line simulation or "post-mortem analysis" the application to be studied is instrumented before being in a real-world environment. Data about the program execution, including periods of computation, the start and end of any communication events, and possibly additional information such as the memory footprint at various points in time, is logged to a trace file.
These traces can then be "replayed" in a simulated environment, considering different "what-if?" scenarios such as a faster or slower network, or more or less powerful processors on some nodes. This trace replay is usually much faster than direct execution, as the computation and communications are not actually executed but abstracted as trace events. A number of tools\cite{dimemas,loggopsim_10,psins_09,nunez_sc10,phantom_10,hermanns_pdnp09}, including SMPI, support the off-line approach.
Off-line simulation carries with it a number of caveats: It assumes that programs are essentially deterministic, and each node will execute the same sequence of computation and communication events regardless of the order in which messages are received. A bigger challenge is that it is extremely difficult to predict the result of changing the number of nodes–while there is considerable interest and research in this area\cite{loggopsim_10,scalaextrap,pmac_lspp13}, the difficulty of predicting the execution profile of programs in general, and the fact that both applications and MPI implementations are likely to vary their behavior based on problem and message size, suggests that reliably guaranteeing results that are accurate within any reasonable bound may be impossible in the general case. Another problem with this approach is that instrumentation of the program can add delays, particularly if the program carries out large numbers of fine-grained network communications, and if this is not carefully accounted for then the captured trace may not be representative of the program in its "natural" state.
By contrast, the on-line approach relies on the execution of the program within a carefully-controlled real-world environment: computational sections are executed in full speed on the available hardware, but timing and delivery of messages are determined by the simulation environment (in the case of SMPI this is provided by SimGrid). This approach is much faster than full emulation (although slower than trace replay), yet preserves the proper ordering of computation and communication events. This is the standard approach for SMPI, and a number of other simulation toolkits and environments also followed this approach\cite{mpi-netsim_09, dickens_tpds96, bagrodia_ijhpca01, riesen_iccc06}.
To support simulations at very large scale, SMPI allows for shadow execution and to trade off accuracy for simulation speed by benchmarking the execution of program blocks a limited number of time, while skipping these blocks later on and inserting a computation time in the simulated system clock based on the benchmarked value. This corrupts the solution produced by the application, but for data independent applications (those whose behavior does not depend on the results of the computations) this is likely to result in a reasonably accurate execution profile. A related technique, also provided by SMPI, is memory folding, whereby multiple simulated processes can share a single copy of the same malloc'd data structure. Again, this can corrupt results and potentially result in inconsistent or illegal data values, but allows larger scale simulations than what would be possible otherwise, and may be reasonable for a large class of parallel applications. These features are disabled by default, and have to be enabled by an expert user by adding annotations to the application source code. Potential areas for future work include improving this process so that it can be semi-automated, and building more sophisticated models based on benchmarked values.
4 A "Hybrid" Network Model
\label{sec:hybrid}
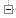
In this section, we report some issues that we encountered when comparing the predictions given by existing models to real measurement on a commodity cluster with a hierarchical Ethernet-based interconnection network. The observed discrepancies motivate the definition of a new hybrid model building upon LogGPS and fluid models, that captures all the relevant effects observed during this study. All the presented experiments were conducted on the graphene cluster of the Grid'5000 experimental testbed\cite{graphene,grid5000}. This cluster comprises 144 2.53GHz Quad-Core Intel Xeon x3440 nodes spread across four cabinets, and interconnected by a hierarchy of 10 Gigabit Ethernet switches (see Figure\ref{fig.graphene}).
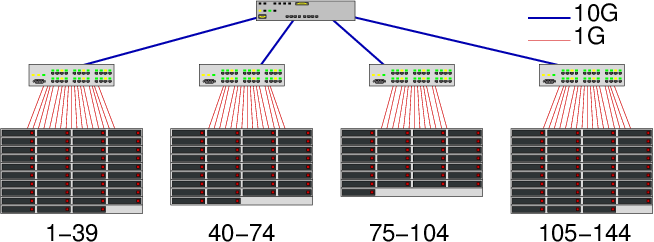
Figure 2: The graphene cluster: a hierarchical Ethernet-based cluster.
4.1 Point-to-point communication model
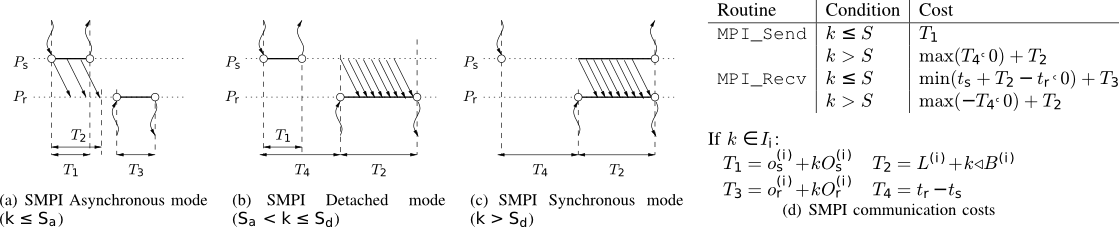
Figure 3: The "hybrid" network model of SMPI in a nutshell.
As described previously in Section\ref{sec:models}, models in the LogP family
resort to piece-wise linear functions to account for features such as protocol
overhead, switch latency, and the overlap of computation and communication. In
the LogGPS model\cite{LogGPS} the time spent in the MPI_Send and MPI_Recv
functions is modeled as a continuous linear function for small messages
(\(o+kO_s\) or \(o+kO_r\)). Unfortunately, as illustrated in
Figure\ref{fig.smpi_os_piecewise_linear}, this model is unable to account for
the full complexity of a real MPI implementation. The measurements presented in
Figure\ref{fig.smpi_os_piecewise_linear} were obtained according to the
following protocol: To avoid size and sequencing measurement bias, the message
size is exponentially sampled from 1 byte to 100MiB. We ran two "ping" and one
"ping-pong" experiments. The ping experiments aim at measuring the time spent in
the MPI_Send (resp. MPI_Recv) function by ensuring that the receiver (resp.
sender) is always ready to communicate. The ping-pong experiment allows us to
measure the transmission delay. We ran our analysis on the whole set of raw
measurements rather than on averaged values for each message size to prevent
behavior smoothing and variability information loss. The rationale is to study
the asynchronous part of MPI (from the application point of view) without any a
priori assumptions on where switching may occur. This approach allows us to
clearly identify different modes interpreted as follows:
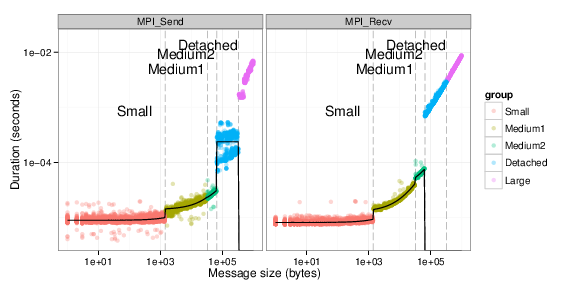
Figure 4: MPI_Send and MPI_Recv duration as a function of message size.
- Small (when \(k\leq1,420\)): this mode corresponds to messages that fit in a TCP packet and are sent asynchronously by the kernel. As it induces memory copies, the duration significantly depends on the message size.
- Medium (when \(1,420
- Detached (when \(65,536
- Large (when \(k>327,680\)): for such messages, both sender and receiver synchronize using a rendez-vous protocol before sending data. Except for the waiting time, the durations on the sender side and on the receiver side are very close.
- Detached (when \(65,536
As illustrated by Figure\ref{fig.smpi_os_piecewise_linear}, the duration of
each mode can be accurately modeled through linear regression. These
observations justify the model implemented in SMPI that is described in
Figure\ref{fig.smpi_models}. We distinguish three modes of operation:
asynchronous, detached, and synchronous. Each of these modes can be divided in
sub-modes when discontinuities are observed. The "ping" measurements are used to
instantiate the values of \(o_s\), \(O_S\), \(o_r\), and \(O_r\) for small to detached
messages. By subtracting \(2(o_r+k.O_r)\) from the round trip time measured by the
ping-pong experiment, and thanks to a piece-wise linear regression, we can
deduce the values of \(L\) and \(B\). It is interesting to note that similar
experiments with MPI_Isend and MPI_Irecv show that modeling their duration
by a constant term \(o\) as was done in\cite{LogGPS} is not a reasonable
assumption neither for simulation nor prediction
While distinguishing these modes may be of little importance when simulating applications that only send particular message sizes, obtaining good predictions in a wide range of settings, and without conducting custom tuning for every simulated application, requires accurately accounting for all such peculiarities. This will be exemplified in Section\ref{sec:validation}.
4.2 Topology and contention model
For most network models, dealing with contention comes down to assuming one of the simple single-port or multi-port models. In the single-port model each node can communicate with only one other node at a time and messages are queued, while in the multi-port model, each node can communicate with every other node simultaneously without any slowdown. Both models oversimplify the reality. Some flow-level models follow a bounded multi-port approach\cite{HP_TPDS07}, \ie the communication capacity of a node is limited by the network bandwidth it can exploit, that better reflects the behavior of communications on wide area networks. However, within a cluster or cluster-like environment the mutual interactions between send and receive operations cannot safely be ignored.
To quantify the impact of network contention of a point-to-point communication between two processors in a same cabinet, we artificially create contention and measure the bandwidth as perceived by the sender and the receiver. We place ourselves in the large message mode where the highest bandwidth usage is observed and transfer 4 MiB messages.
In a first experiment we increase the number of concurrent transfers from 1
to 19, i.e., half the size of the first cabinet. As the network switch is well
dimensioned, this experiment does not create contention: We observe no bandwidth
degradation on either the sender side or the receiver side. Our second
experiment uses concurrent MPI_Sendrecv transfers instead of unidirectional
transfers. We increase the number of concurrent bidirectional transfers from 1
to 19 and measure the bandwidth on the sender (\(B_s\)) and receiver (\(B_r\)) side.
A single-port model, as assumed by LogP-based models, would lead to \(B_s+B_r =
B\) on average since both directions strictly alternate. A multi-port model, as
assumed by other delay models, would estimate that \(B_s+B_r = 2 \times B\) since
communications would not interfere with each other. However, both fail to model
what actually happens, as we observe that \(B_s+B_r \approx 1.5\times B\) on this
cluster.
We model this bandwidth sharing effect by enriching the simulated cluster description. Each node is provided with three links: an uplink and a downlink, so that send and receive operations share the available bandwidth separately in each direction; and a specific limiter link, whose bandwidth is \(1.5 \times B\), shared by all the flows to and from this processor.
Preliminary experiments on other clusters show that this contention parameter seems constant for a given platform, with a value somewhere between 1 and 2. Such value somehow corresponds to the effective limitation due to the card capacity and the protocol overhead. Determining this parameter requires benchmarking each cluster as described in this section. Our set of experiments is available on the previously indicated web page. We are currently working on a more generic benchmarking solution that one could easily use to determine the exact contention factor for any cluster.
This modification is not enough to model contention at the level of the whole graphene cluster. As described in Figure\ref{fig.graphene}, it is composed of four cabinets interconnected through 10Gb links. Experiments show that these links become limiting when shared between several concurrent pair-wise communications between cabinets. This effect corresponds to the switch backplane and to the protocol overhead and is captured by describing the interconnection of two cabinets as three distinct links (uplink, downlink, and limiter link). The bandwidth of this third link is set to 13 Gb as measured.
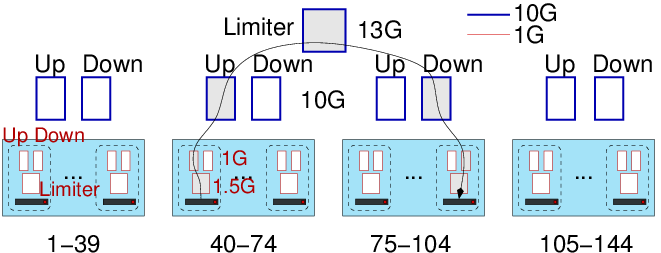
Figure 5: Modeling the graphene cluster: rectangles represent capacity constraints. Grayed rectangles represent constraints involved in a communication from node to node 40 to node 104.
The resulting topology is depicted on Figure\ref{fig.graphene_sg} and is easily described in a compact way within SimGrid. Since SimGrid, on which SMPI is based, is a versatile simulator, incorporating further levels of hierarchy or more complex interconnections if needed would be easy\cite{simetierre}.
4.3 Collective communications model
Many MPI applications spend a significant amount of time in collective
communication operations. They are thus crucial to application performance.
Several algorithms exist for each collective operation, each of them exhibiting
very different performance depending on various parameters such as the network
topology, the message size, and the number of communicating
processes\cite{star-mpi}. A given algorithm can commonly be almost an order of
magnitude faster than another in a given setting and yet slower than this same
algorithm in another setting. Every widely-used MPI implementation thus provides
several algorithms for each collective operation and carefully selects the best
one at runtime. For instance, OpenMPI provides a dozen distinct algorithms for
the MPI_Alltoall function, and the code to select the right algorithm for a
given setting is several thousand lines long. Note that the selection logic of
the various MPI implementations is highly dependent on the implementation and
generally embedded deep within the source code.
Our [in]validation experiments quickly highlighted the importance of adhering as closely as possible to this logic. Hence SMPI now implements all the collective algorithms and selection logics of both OpenMPI and MPICH and even a few other collective algorithms from Star MPI\cite{star-mpi}. Deciding which selector and which algorithms are used can be specified from command line, which allows users to test within simulation whether replacing a default algorithm by another may help or not on a particular combination of platform/application.
5 Model [In]Validation Experiments
\label{sec:validation}
5.1 Methodology
All the experiments presented hereafter have been done on the graphene cluster that was described in the previous section. The studied MPI applications were compiled and linked using OpenMPI 1.6. For comparison with simulated executions purposes, we instrumented these applications with TAU\cite{shende06}. The simulated executions have been performed either off-line or on-line as SMPI supports both modes. The file describing the simulated version of the graphene cluster was instantiated with values obtained independently from the studied applications. We used the techniques detailed in the previous section to obtain these values. In what follows we compare execution times measured on the graphene cluster to simulated times obtained with the hybrid model proposed in Section\ref{sec:hybrid}, the LogGPS model that supersedes all the delay-based models, and a fluid model that is a basic linear flow-level model whose validation for WAN studies was done in\cite{Velho_TOMACS13}.
We did not limit our study to overall execution times as they may hide compensation effects, and do not provide any information as to whether an application is compute or communication bound or how different phases may or may not overlap. Our experimental study makes use of Gantt charts to compare traces visually as well as quantitatively. We rely on CSV files, R, and org-mode to describe the complete workflow going from raw data the graphs presented in this paper, ensuring full reproducibility of our analysis.
\AL{I don't know if the previous paragraph should stay since our org file is not the cleanest thing either…} \MS{I think that referencing workflows from docs is good, but maybe including all of the analysis code in the file is not the best.}
5.2 NAS Parallel Benchmarks
The NAS Parallel Benchmarks (NPB) are a suite of programs commonly used to assess the performance of parallel platforms. In this article, we only report results for two of these applications but results for other applications are also available in\cite{bedaride:hal-00821446}. The LU benchmark is an iterative computation of a LU factorization. At each iteration, it exhibits a communication scheme that forms a wave going from the first process to the last one and back. The second studied benchmark is CG (Conjugate Gradient). It has a complex communication scheme that is composed of a large number of point-to-point transfers of small messages. Moreover, processors are organized in a hierarchy of groups. At each level communications occur within a group and then between groups. This benchmark is then very sensitive to the mapping of the MPI processes on to the physical processors with regard to network organization, particularly in non-homogeneous topologies. For this series of experiments, we use the off-line simulation capacities of SMPI, i.e., execution traces of the benchmark are first acquired from a real system and then replayed in a simulated context.
Both benchmarks are evaluated with two class of instances, B, and C, where C is the larger instance. A classical goal when studying the performance of an application or of a new cluster is to evaluate how well the application scales for a given instance. Figure\ref{fig:NPB_comparison} shows the speedup as measured on the graphene cluster and as obtained with the studied models. For every experiment we ensured that both simulated and real node mapping corresponds to each others.
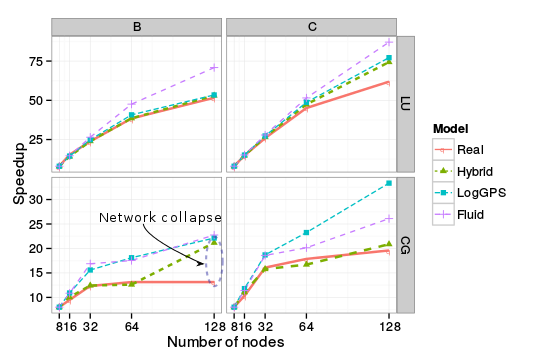
Figure 6: Comparison between simulated and actual execution times for three NAS parallel benchmarks.\label{fig:NPB_comparison}
For the LU benchmark we can see that for the class B instances, the hybrid and LogGPS model provide an excellent estimation of speedup evolution. As could be expected, the fluid model provides an over-optimistic estimation, which can be explained by its poor ability to accurately model transmission time of small messages and computation/communication overlap. For the class C instance, although the hybrid model provides a slightly better estimation than the LogGPS model, both predict an optimistic scaling of this application. We think, this can be explained by the fact that none of these models include a noise component. Indeed, the communication pattern of LU is very sensitive to noise as each process has to wait for the reception of a message before sending its own data. Such a phenomenon is given by Figure\ref{fig:LU_gantt_zoom} that shows a period of 0.2 seconds of the execution of the LU benchmark with 32 processes. The upper part of this figure displays the actual execution while the lower corresponds to the simulation of the same phase with the hybrid model. Deterministic models such as LogGPS or hybrid slightly underestimate these synchronization phases and small delay adds up, which hinders the application scalability. However, Figure\ref{fig:LU_gantt_zoom} clearly shows that despite the small time scale, the simulation correctly renders the general communication pattern of this benchmark and that Figure\ref{fig:NPB_comparison} does not hide a bad, but lucky, estimation of each component of the execution time.
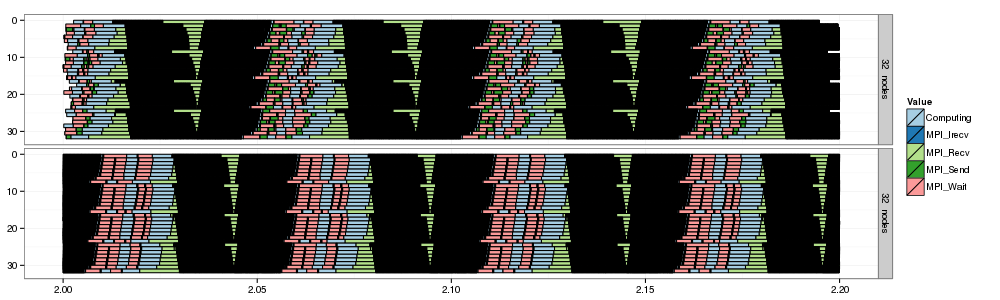
Figure 7: Part of the Gantt chart of the execution of the LU benchmark with 32 processes. The upper part displays the actual execution while the lower is the simulation with the hybrid model. Black areas comprise thousands wave-structured micro messages.
The results obtained for the CG benchmark are more discriminating. Indeed, this benchmark transfers messages that never fall in the large category. As can be observed, both the LogGPS and fluid models fail to provide good estimations and largely underestimate the total time. Our hybrid model produces excellent estimation except on the class B instance with 128 nodes. To determine if the source of this gap comes from a bad estimation by the model or a problem during the actual execution, we compared more carefully the two traces. Our main suspect was the actual execution, which is confirmed by the Gantt chart presented in Figure\ref{fig:CG_gantt_zoom}.
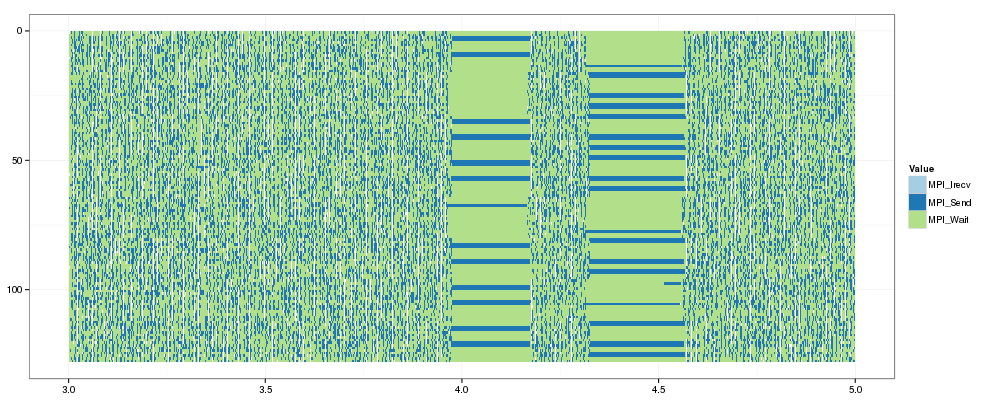
Figure 8: Two seconds Gantt-chart of the real execution of a class B instance of CG for 128 process.
The execution time on the class B instance is 14.4 seconds while the prediction
of the hybrid model is only of 9.9 seconds. We can see two outstanding zones
of MPI_Send and MPI_Wait. Such operations typically take few microseconds to
less than a millisecond. Here they take 0.2 seconds. Our guess is that, due to a
high congestion, the switch drops packets and slows down one (or several)
process to the point where it stops sending until a timeout of .2 seconds is
reached. Because of the communication pattern, blocking one process impacts all
the other processes. This phenomenon occurs 24 times leading to a delay of 4.86
seconds. Without this bad behavior, the real execution would take 9.55 seconds,
which is extremely close to the 9.85 seconds prediction of the hybrid model
and would allow the effective speedup to match perfectly its prediction. The
same phenomenon is also present for class C although it is less noticeable. In
both cases, the speedup shape predicted by the hybrid model is non-trivial
since it comprises a plateau from 32 to 64 nodes. Such shape can actually be
well explained by the hierarchical structure of its communication pattern and
how it maps to the network topology. The LogGPS model fails at modeling such
aspects and would predict an excellent scaling.
Although we do not know for sure yet, we think the timeout issues we encountered could be somehow similar to what is known as the TCP incast problem and which has been observed in cloud environments\cite{Chen_incast_2009}. Such delays are linked to the default TCP re-transmission timeout, which is equal to .2s by default in Linux. Although such value has recently been decreased from 1s to .2s to adapt with recent evolution of Internet characteristics, it remains inadequate for a cluster. Such protocol collapse would clearly need to be fixed in a production environment and we are currently investigating whether decreasing the TCP re-transmission timeout to a drastically smaller value than .2 seconds would help or not as it is not clear that HPC variants of TCP would really help solving such issue.
5.3 Collective Communications
The NAS parallel benchmarks do not heavily rely on MPI collective
communication primitives but instead implement a static communication pattern.
We conduct the (in)validation with the study of an isolated MPI collective
operation at a time. On medium size clusters, simple operations like broadcast
only incur minor network contention toward the end of the operation and may thus
be correctly predicted with simple models like LogGPS. Therefore, although we
conducted similar studies for most commonly used operations, we only report the
results for the MPI_Alltoall function as it is the most likely to be impacted
by network contention. Here we aim at assessing the validity of contention
modeling as the message size varies rather than the impact of using different
algorithms. To this end, although we extended SMPI so that it implements all
the collective algorithms and selection logics of both OpenMPI and MPICH, we
enforce the use of a single algorithm, i.e., the pairwise-exchange
algorithm\cite{mpich}, for all message sizes. We ran the experiment five times
in a row and only kept the best execution time for each message size. Indeed, we
noticed that the first communication is always significantly slower than the
subsequent ones, which tends to indicate that TCP requires some warm-up time.
This phenomenon has also been noticed in experiments assessing the validity of
the BigSIM simulation toolkit, where the same workaround was applied.
options( width = 200 ) library(plyr) library(ggplot2) df = data.frame() for(file in c("alltoall/hybrid.csv", "alltoall/RL.csv", "alltoall/fluid.csv", "alltoall/logp.csv")) { d <- read.csv(file,header=T, strip.white=TRUE) d$Origin=file df <- rbind(df,d) } df$Model = gsub(".*/","", df$Origin) df$Model = gsub(".csv","", df$Model) df$Model = gsub("RL","Real", df$Model) df$Model = gsub("hybrid","Hybrid", df$Model) df$Model = gsub("fluid","Fluid", df$Model) df$Model = gsub("logp","LogGPS", df$Model) df = df[!(names(df) %in% c("X","Origin"))] library(reshape) df <- melt(df, id=c("procs","Model")) # facet_wrap(~Problem,nrow=1,scales="free") + df$Model <- factor(df$Model, levels=c("Real","Hybrid","LogGPS","Fluid")) df$Size = df$variable df = df[!(names(df) %in% c("variable"))] df <- df[df$procs>=4 & df$Size!="small",] ggplot(df,aes(x=procs,y=value,color=Model,shape=Model,linetype=Model)) + theme_bw() + geom_line() + geom_point(size=2) + scale_x_log10(breaks=unique(df$procs)) + scale_y_log10(breaks=c(.01,.1,1,10)) + facet_wrap(~Size,,nrow=1,scales="free") + ylab("Duration (seconds)") + xlab("Number of MPI Processes")
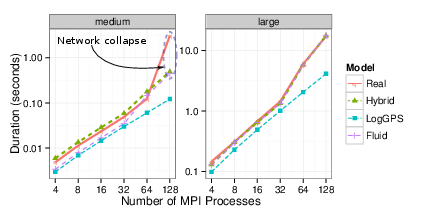

Figure 10: Comparison between simulated and actual execution times for the MPI_Alltoall operation.
cat manual.csv cg.csv dt.csv lu.csv > all.csv
Figure\ref{fig:all2all_comparison} shows (in logarithmic scale) the evolution of
simulated and actual execution times for the MPI_Alltoall operation when the
number of MPI processes varies for the three network models. Results are
presented for two message sizes: medium messages of 100 kiB and large
messages of 4 MiB. We can see that for large messages, the hybrid and fluid
models both achieve excellent predictions (within 10%). Unsurprisingly, the
LogGPS model is overly optimistic in such setting and completely
underestimates the effects of network contention. Its prediction error can be
up to a factor of 4 when 128 processors are involved in the All-to-All
operation.
For medium messages, the hybrid model is again the best contender, with a low prediction error for up to 64 nodes, while the LogGPS model is again too optimistic. For such a message size, the lack of latency and bandwidth correction factors in the fluid model leads to a clear underestimation of the execution time. Interestingly, when 128 processes are involved in the collective communication, the actual execution time increases dramatically while simulated times continue to follow the same trend. The reason for such a large increase can again be explained by massive packet dropping in the main switch that leads to timeouts, and unexpected re-emissions, hence incurring significant delays compared to usual transmission time. Modeling such phenomenon would probably be quite difficult and of little interest since fixing this problem on the real platform would be much more useful.
6 Simulating a Real Application
\label{sec:bigdft}
Developing a research prototype that allows for simulation of a few benchmarks already requires a lot of efforts and is useful to demonstrate the effectiveness of an idea. However, it does not allow others to build upon it. Therefore, we also ensured SMPI could also be used to simulate complex real applications such as the full LinPACK suite\cite{Dongarra03thelinpack}, Sweep3D\cite{sweep3d}, or BigDFT, which is an open-source Density Functional Theory (DFT) massively parallel electronic structure code\cite{genovese2008daubechies}, and the geodynamics application SpecFEM3D\cite{specfem3d}, which is part of the PRACE benchmark. SMPI also is tested upon 80% of the MPICH2 test suite and against a large subset of the MPICH3 test suite every night. We can thus claim that SMPI is not limited to toy applications but can effectively be used for the analysis of real scientific applications.
In this section we aim at demonstrating the capacity of SMPI to simulate a real, large, and complex MPI application. To this end, we use BigDFT, which is the sole electronic structure code based on systematic basis sets which can use hybrid supercomputers and is able to scale particularly well (95\% of efficiency with 4096 nodes on Curie \cite{Curie}). This is why it is one of the eleven real scientific applications that have been selected in the Mont-Blanc project\cite{montblanc} to assess the potential of low-power embedded components based clusters to address future Exascale HPC needs. One of the objectives of the Mont-Blanc project is thus to develop prototypes of HPC clusters using low power commercially available embedded technology such as ARM processors and Ethernet technologies.
The first Mont-Blanc prototype is expected to be available during the year 2014. It will be using Samsung Exynos 5 Dual Cortex A15 processors with an embedded Mali T604 GPU and will be using Ethernet for communication. In order to start evaluating the applications before 2014, a small cluster of ARM system on chip was built. It is named Tibidabo and is hosted at the Barcelona Supercomputing Center. Tibidabo\cite{rajovic_tibidabo} is an experimental HPC cluster built using NVIDIA Tegra2 chips, each a dual-core ARM Cortex-A9 processor. The PCI Express support of Tegra2 is used to connect a 1Gb Ethernet NIC, and the board are interconnected hierarchically using 48-port 1 GbE switches. The results we present in this section have been obtained using this platform.
For our experiments, we disable the OpenMP and GPU extensions at compile time to study behaviors related to MPI operations. BigDFT alternates between regular computation bursts and important collective communications. Moreover the set of collective operations that is used may completely change depending on the instance, hence the need to use online simulation. In the following experiments, we used MPICH 3.0.4\cite{mpich} and Extrae\cite{extrae} for runtime incompatibility issues between OpenMPI, Tau and BigDFT. Last, while this application can be simulated by SMPI without any modification to the source code, its large memory footprint means that running the simulation on a single machine would require an improbably large amount of RAM. Applying the memory folding and shadow execution techniques mentioned in Section\ref{sec:framework} and detailed in\cite{SMPI}, we were able to simulate the execution of BigDFT with 128 processes, whose peak memory footprint is estimated to 71 GiB, on a single laptop using less than 2.5GB of memory. Such memory requirement could be further improved with additional manual annotations but it was sufficient for our needs.
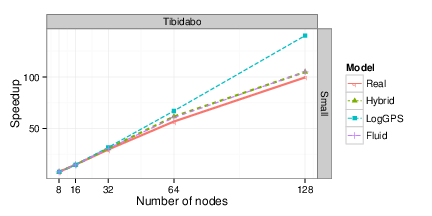
Figure 11: Evaluating scalability of BigDFT on Tibidabo both through real executions and simulation. The LogGPS model fails to model the slowdown incurred by the hierarchical and irregular network topology.\label{fig:BigDFT_comparison}
Figure\ref{fig:BigDFT_comparison} shows the comparison of the speedup evolution
as measured on the tibidabo cluster on a small instance. This instance has a
relatively low communication to computation ratio (around 20% of time is spent
communicating when using 128 nodes and the main used operations are
MPI_Alltoall, MPI_Alltoallv, MPI_Allgather, MPI_Allgatherv and
MPI_Allreduce) despite the slow computations of tibidabo. This instance is
thus particularly difficult to model and is expected to have a limited
scalability, which one may want to observe in simulation first to avoid wasting
resources or to assess the relevance of upgrading hardware. As expected, the
LogGPS model predicts an over-optimistic perfect scaling whereas both the
fluid and the hybrid models succeed in accounting for the slowdown incurred
by the hierarchical and irregular network topology of this prototype platform.
We think this kind of observation really questions the use of the LogGPS model
for scalability studies.
To further demonstrate the usability of our tool, we want to mention that simulating 64 nodes of tibidabo, which is made of relatively slow ARM processors, on a Xeon 7460 with partial on-line simulation takes twice as less time (10 minutes) than running the code for real (20 minutes).
7 Related Work
\label{sec:related}
Packet-level network simulations are usually implemented as discrete-event simulations with events for packet emission or reception as well as network protocol events. Such simulations reproduce the real-world communication behavior down to movements of individual packets. Some tools following this approach, e.g., NS2, NS3, or OMNet++, have been widely used to design network protocols or understand the consequences of protocol modifications\cite{omnetpp_HPC_09}. However, such fine-grain network models are difficult to instantiate with realistic parameter values for large-scale networks and generally suffer from scalability issues. While parallel discrete-event simulation techniques\cite{bigsim_04, ROSS_SC12} may speed up such simulations, the possible improvements remain quite limited.
Some projects model MPI collective communications with simple analytic formulas\cite{dimemas, psins_09}. This allows for quick estimations and may provide a reasonable approximation for simple and regular collective operations, but is unlikely to accurately model the complex optimized versions that can be found in most MPI implementations. An orthogonal approach is to thoroughly benchmark collective operations to measure the distribution of communication times with regard to the message size and number of concurrent flows. Then, these distributions are used to model the interconnection network as a black box\cite{adelaide_05}. This approach has several drawbacks. First, it does not accurately model communication/computation overlap. Second, it cannot take the independence of some concurrent communications into account. Third, it provides little to no information on how the performance of collective operations could be improved. Finally, it does not allow for performance extrapolation on a larger machine with similar characteristics and it provides little insight into the causes of poor performance. A third approach consists in tracing the execution of collective operations and then replaying the obtained trace using one of the aforementioned delay models\cite{loggopsim_10, bigsim_04,dimemas,psins_09}. However, most tools\cite{loggopsim_10,psins_09,dimemas,dickens_tpds96} use a very basic network topology model that does not account for the complexity of modern platforms. Furthermore, current implementations of the MPI standard dynamically select from up to a dozen different communication algorithms when executing a collective operation depending on message size and on the number of involved nodes. Thus, using the right algorithm becomes critical when trying to predict performance.
Studying the behavior of complex HPC applications or operations and characterizing HPC platforms through simulation has been at the heart of many research projects and tools for decades. Such tools differ by their capabilities, their structure, and by the network models they implement. BigSIM\cite{bigsim_04}, LAPSE\cite{dickens_tpds96}, MPI-SIM\cite{bagrodia_ijhpca01}, or the work in\cite{riesen_iccc06} rely on simple delay models (affine point-to-point communication delay based on link latency and bandwidth). Other tools, such as Dimemas\cite{dimemas}, LogGOPSim\cite{loggopsim_10}, or PHANTOM\cite{phantom_10} use variants of the LogP model to simulate communications. Note that BigSIM also offers an alternate simulation mode based on a complex and slow packet-level simulator. This approach is also followed by MPI-NeTSim\cite{mpi-netsim_09} that relies on OMNeT++. Finally PSINS\cite{psins_09} and PEVPM\cite{adelaide_05} provide complex custom models derived from intensive benchmarking to model network contention.
8 Conclusion and Future Work
\label{sec:ccl}
In this paper, we demonstrated that accurate modeling and performance prediction for a wide range of parallel applications requires proper consideration of many aspects of the underlying communication architecture, including the breakdown of collective communications into their component point-to-point messages, the interconnect topology, and contention between competing messages that are sent simultaneously over the same link. Even relatively minor inaccuracies may compromise the soundness of the simulation, yet none of the models previously used in the literature give due consideration to these factors. We described the implementation of a proposed hybrid network model that improves on this situation within SMPI, and showed that SMPI-based simulations do a better job of tracking real-world behavior than those implemented in competing simulation toolkits.
Our priority in this work was the validation of the model at a small scale and for TCP over Ethernet networks. However, we also believe that SMPI will prove very useful to application developers by allowing them to debug parallel applications and study the impact of selecting different collective communication algorithms without wasting cluster resources. It also provides a good comparison point that helps determine whether or not the platform and application behave as expected. Previous models are expected to provide over optimistic evaluations and are thus of little use. Finally, we think this tool will prove very useful to efforts such as the European Mont-Blanc project\cite{montblanc, rajovic_tibidabo}, which aims at prototyping exascale platforms using low-power embedded processors interconnected by Ethernet. A next step will be to analyze its adequacy for simulating larger platforms when such machines become available for benchmarking purposes. The study should then extend to other kinds of interconnects (such as InfiniBand) and more complicated topologies (e.g., torus or fat trees).
As a base line, we advocate for an open-science approach, which should enable other scientists to reproduce the experiments done in this paper. For that purpose, the traces and scripts used to produce our analysis are available\cite{smpi_sc13_figshare_traces}. Accordingly, SMPI and all the software stack are provided as open-source software available for download from the SimGrid website:
9 Acknowledgments
This work is partially supported by the SONGS ANR project (11-ANR-INFRA-13), the CNRS PICS \(N^{\circ}\) 5473, the European Mont-Blanc project (European Community’s Seventh Framework Programme [FP7/2007-2013] under grant agreement no 288777). Experiments presented in this paper were carried out using a PRACE (European Community funding under grants RI-261557 and RI-283493) prototype and the Grid'5000 experimental testbed, being developed under the INRIA ALADDIN development action with support from CNRS, RENATER and several Universities as well as other funding bodies (see https://www.grid5000.fr). We would also like to thank Luigi Genovese, main developer of BigDFT, who helped us with porting this code on top of SMPI and using interesting problem instances.
\bibliographystyle{abbrv} \bibliography{smpi_sc13}