RICM4: Évaluation de Performance 2018
Table of Contents
Sitemap
|
|




Informations Générales
Le pad du cours est ici: https://tinyurl.com/RICM4-2018 (moved at https://tinyurl.com/evalperf)
Le planning avec les salles de cours est disponible ici.
La page de l'an dernier est ici.
Programme du cours
| Semaine | Cours (Jeudi, 8h00 en 035) | TD (Vendredi, 11:30 ou exceptionnellement 8:00) |
|---|---|---|
| 17-18 janvier | Introduction au cours et aux files d'attente et Simulation d'une M/M/1 en R (voir le pad) | Simulation à évènement discret d'une M/M/1 |
| 24-25 janvier | Modélisation des files d'attente et des systèmes Markoviens. | Pas de TD |
| 31-1 février | Chaînes de Markov à Temps Discret Pour ceux qui veulent un rappel sur les valeurs propres. | Études de petits systèmes Markovien et d'un cache Web (correction et code R) + présentation du DM |
| 7-8 février | Chaînes de Markov à Temps Discret: LRU, M/M/1 aux instants de sauts | |
| 14-15 février | Analyse des logs d'un serveur Web et Introduction au Processus de Poisson | Poursuite de l'analyse des logs et propriétés du processus de Poisson (interarrivé, uniformité,…). Autres références avec les preuves (Cours Geneviève Gauthier , cours Étienne Pardoux) |
| 21-22 février | Processus de Poisson | Page rank |
| 28-1 mars | Vacances | Vacances |
| 7-8 mars | Chaîne de Markov à temps continu | Aloha! |
| 14-15 mars | Quick | Processus de naissance et de mort, file M/M/1 |
| 21-22 mars | Little, calcul complet d'une M/M/1, et d'une M/M/1/C | TD sur les iles d'attente. En bonus, un aide mémoire sur la M/M/1 et sur la M/M/K/K. |
| 28-29 mars | Régression linéaire | La régression linéaire en pratique + open questions |
| 5 avril | Réseaux de Jackson | |
| 8 avril | Examen le lundi 5 avril à 8h00 |
Retour sur le DM
- Leya BADAT et Victor CUAU
- (bonus) A++ Très bon travail. Attention
cependant aux points suivant:
- Vous tracez des intervalles de confiance en faisant
sd(Energy)alors que vous n'avez qu'une seule valeur. Vos intervalles de confiance n'ont dont pas de sens. Il faudrait pour avoir des intervalles de confiance définir une durée fixe \(D\), et calculer dans votre simulation de durée \(T\), des statistiques sur les \(T/D\) intervalles de temps correspondants. Hélas, une fois de plus pour ce type de simulation, vos mesures ne seraient pas indépendentes et il faudrait considérer vos intervalles de confiance avec précaution. Pour le coup, la consommation énergétique étant linéaire avec la charge, une régression linéaire aurait été parfaitement adapté pour déterminer la charge au delà de laquelle le serveur 2 consomme plus que le serveur 1. Ça aurait été particulièrement efficace pour la comparaison du serveur 2 au serveur 3. - L'allure du temps de réponse du serveur 3 est vraiment surprenante (ça zigzague un peu trop). Probablement aurait-il fallu des simulations un peu plus longues pour les charges plus élevées.
- Vous tracez des intervalles de confiance en faisant
- Mathieu DUMAX-VORZET
- A- Un travail sérieux mais il faut que tu
soit plus critique avec tes observations et plus rigoureux.
- Quelle drôle d'idée de charger tes serveurs largement au delà de leur capacité. Comme tu le dis, les valeurs mesurées n'ont alors aucun sens. Du coup, tu ne peut pas vraiment voir les zones intéresantes (en particulier à faible charge). Tu pourras vérifier que quand tu augmentes la durée de la simulation, l'échelle de tes courbes va énormément changer et donc difficile de faire confiance aux valeurs que tu calcules.
- Par contre, même si tes simulations sont courtes (N=300), tu as fait plusieurs simulations et ça c'est une bonne idée. C'est ça qui te permet d'obtenir des "intervalles de confiance" (erm) sur la consommation énergétique.
- Tes
ribbonssont de largeur l'écart-type mesuré. Ce ne sont pas des intervalles de confiance puisque tu ne divises pas par la racine du nombre d'échantillons (du nombre de simulations dans le cas de la consommation énergétique). - Quand je vois la taille de tes
ribbons, je te trouves bien confiant pour arriver à évaluer le seuil à 0.18… Il se trouve que c'est la bonne valeur mais tu n'aurais pas du faire confiance à ce résultat. - Aïe aïe aïe. Tu vois, encore une fois, tu fais bien trop confiances à ce que tu mesures. La courbe de consommation énergétique du serveur 2 et du serveur 3 ne se croisent qu'une seule fois. Il se trouve que vu que la consommation énergétique d'un serveur est bornée, ça va effectivement se recroiser mais tu n'as aucun moyen de le voir avec aussi peu de valeurs. Ce que tu vois là, c'est principalement du bruit. Si tu refaisais la simulation avec une graine différente tout ça aurait une allure assez différente. Il faut que tu sois plus méfiant et plus critique.
- Tanguy SAUTON et Mathieu VINCENT
- B
- C'est balot, ce
resp_sdque vous calculez mais n'utilisez jamais. Au passage, utilisezn()(qui comptera le nombre d'échantillons) plutôt quen(qui est une constante que vous avez défini) dans ce calcul. - Et plutôt que de calculer des intervalles de confiance comme vous
êtes sensés savoir le faire, Vous utilisez une fonction
(
geom_smooth(method = 'loess')) que vous ne comprenez pas et qui n'a vraiment aucun sens ici! Déjà, sur la courbe de charge comparant \(S_1\) et \(S_2\), ça se voyait mais celle avec \(S_3\), c'est … comment dire? Sérieusement, vous n'avez pas trouvé ça anormal? C'est pour le dernier graphe que c'est le moins "horrible" car les comportements sont linéaires et encore, vous auriez du trouver ça bizarre une consommation énergétique (pour \(S_2\)) qui diminue quand la charge augmente. - Pareil, quand vous indiquez \(\lambda_{pivot}= 0.18\pm 0.1\). D'où sort ce 0.1? Et puis ça veut dire que selon vous, il est entre 0.08 et 0.028? C'est quand même un peu large comme encadrement, vous ne trouvez pas?
- Alors par contre, votre toute dernière analyse de la consommation énergétique lorsque les serveurs sont surchargés est tout à fait correcte. Mais bon vu qu'à charge pleine, le serveur \(S_2\) ne tient plus la charge…
- C'est balot, ce
- Damien Wykland
- A++ Excellent travail. Bravo!
- Loïc SOUCHON, Loïc SCHANEN et Antoine PELISSON
- A Très bon travail. Mais bon, vous étiez trois…
- Maxence BRÈS
- A++ Très bon travail.
- Guillaume DENIS et Bastien DE ARAUJO
- A- Bon travail dans
l'ensemble mais attention aux points suivants:
- Ça manque de commentaires et quand il y en a, ils sont loin des figures.
- Et la gestion du deuxième processeur… Wow, berk. Deux tableaux
Remaining? Ça marche mais c'est tordu comme idée. - 0.184 et 0.607 ? Si je peux me permettre, c'est un peu trop précis pour être vrai. Il y a des incertitudes dans vos estimations et vous faites comme s'il n'y en avait pas. Et en plus vos droites se croisent à 0.18325, bien plus proche de 0.183 que de 0.184.
- Joachim FONTFREYDE et Yann GAUTIER
- B
- Quelle présentation peu agréable: une platrée de code, 6 graphes, un petit paragraphe d'explications. Tout l'intérêt du R markdown, c'est de pouvoir passer facilemnt de l'un à l'autre pour bien expliquer et faire quelque chose de plus digeste de de plus lisible.
- Attention, votre simulation du serveur S3 est complètement fausse. Un système composé de deux serveurs de vitesse 1 et 2 n'est pas équivalent à un serveur de vitesse 3. Et pour la consommation énergétique, c 'est n'importe quoi ces valeurs.
- Vous dites: En effet on note que lorsque N est égale à 100 le temps de réponse du serveur S1 peut être inférieur à celui de S2 ce qui semble étonnant. Ça pourrait arriver mais ce n'est pas le cas sur vos courbes.
- Ariane ANCRENAZ et Hoël JALMIN
- A++
- Bonne rédaction/présentation/explications
- Vous avez deux paramètres pour décrire la durée de vos simulations: N (le nombre de tâches injectées dans le système) et 200 (même si le commentaire indique 500), le nombre de simulations que vous allez effectuer pour chaque configuration. Vous calculez bien vos intervalles de confiance sur le résultat des 200 simulations, ce qui est tout à fait correct. Vous faites partie des rares à avoir des intervalles de confiance sur la consommation énergétique. Par contre, 100 tâches, quand le système est chargé, ce n'est probablement pas très représentatif de l'état stationnaire. Vous sous-estimez donc le temps de réponse du système. Vos courbes "explosent" moins que ce qu'elles devraient, en particulier quand vous dépassez la capacité du système… Et du coup, vous sur ou sous-estimez les seuils d'efficacité énergétique des différentes situations. Par contre, vous prenez bien soin, vu la taille de vos intervalles de confiance, d'être assez prudents.
- Effectivement, il y a très peu de différence entre les deux situations (temps de service exponentiel vs. déterministe). C'est un peu plus faible et moins variable. Ça change un peu les seuil du coup mais pas de façon fondamentale.
- Antoine DUMENIL et Baptiste BETEND
- C Pas de commentaires dans votre DM ? Je n'en ferai pas non plus du coup.
- Bertrand GILBERT-COLLET et Corentin CHASSEGUET
- A
- En saturant ainsi S1 et S2 (et S3), on ne peut pas voir leur comportemnet à faible charge. C'est vraiment dommage. En plus, les valeurs représentées (temps de réponse moyen) et les intervalles de confiance n'ont vraiment plus aucun sens.
- Erm, pour la comparaison de la consommation énergétique de S1, S2 et S3, vous ne sentez pas qu'il y a comme un problème avec l'allure de vos courbes qui zig-zaguent ? Pour les charges plus élevées vos estimations sont très peu précises et il est difficile de conclure, sauf si on réfléchit à la forme que doivent avoir ces courbes de consommation énergétiques: linéaires par morceau (croissantes au début jusqu'à ce que le serveur soit saturé auquel cas, il tourne à plein régime et a donc une consommation énergétique constante égale à \(P_{max}\) indépentende de \(\lambda\)).
- Rakotoarimalala MANDRESY - Iheb MASTOURA
- A+ Vous êtes les
derniers que je corrige. Je fatigue un peu niveau
commentaire… Dans l'ensemble, c'est pas mal mais les
commentaires manquent parfois de clarté.
- Niveau code, c'est une bonne idée d'avoir fait des fonctions
temps_de_reponse_1,temps_de_reponse_2, … - C'est aussi bien d'avoir montré d'abord avec une charge inférieure à 1, puis inférieure à 2.
- Pour S3, quand vous indiquez la temps de reponse de s2 et s3 en fonction de lambda, en fait c'est S1 et S3 et du coup, on a du mal à distinguer les comportements.
- Niveau code, c'est une bonne idée d'avoir fait des fonctions
- Nathan DALAINE et Léni GAUFFIER
- Rendu en retard. Note à venir.
TDs
Simulation à évènement discrets de file d'attentes
L'objectif du TD est de comprendre la bonne façon d'organiser une simulation à évènement discret (sans reposer trop intensément sur les hypothèse type arrivées de Poisson) avec la notion d'état du système, d'évènements possible et de mise à jour de l'état du système. Si vous lisiez des bouquins qui expliquent comment faire de la simulation à évènement discret, il n'est pas clair que ça vous aiderait vraiment. Le mieux est d'en écrire un ensemble pour que vous compreniez comment procéder. Pour celà, on va s'intéresser au cas simple d'une file d'attente.
Direction, le pad du cours: https://tinyurl.com/RICM4-2018
Modélisation et principe de simulation
- Paramètres du système
- Taux d'arrivée dans le système
lambda(en tâches par seconde) - Taux de service du système
mu(en tâches par seconde) - Politique de service (on va coder FIFO là mais on essaye de coder tout ça de la façon la plus générique possible)
- Taux d'arrivée dans le système
Description des variables d'état importantes:
- Date courante
t - Dates d'arrivées
Arrival: dates calculées à partir d'inter-arrivées (input) - Temps de service
Service: temps générés (input) - Temps résiduel
Remaining: initialisé àNA, passe à Service quand un job arrive dans le système et décroit alors vers 0. - Date de terminaison
Completion: initialisé àNA, passe à la date courantetlorsqueRemainingpasse à 0. - Client actuellement servi
CurrClient(utile pour caractériser la politique de service utilisée): initialisé àNA
J'ai finalement rajouté une variable
NextArrivalqui permet d'éviter des contortions ou des notations un peu lourdes. Cette variable est initialisée à1et sera incrémentée jusqu'à dépasser le nombre de tâches total.- Date courante
- Évolution possible
- Soit une arrivée
- Soit la terminaison d'une tâche
Structure du code:
while(T) { dtA = ... # temps jusqu'à la prochaine arrivée dtC = ... # temps jusqu'à la prochaine terminaison if(is.na(dtA) & is.na(dtC)) {break;} dt = min(dtA,dtC) # Mettre à jour comme il faut. }
Objectif de la séance:
- Avoir une version correcte de cette simulation
- Structurer ce code obtenir une data-frame avec tout ce qu'il faut pour étudier le temps de réponse en fonction du taux d'arrivée:
Fixer le taux de service
muà 1 et étudier (je veux une courbe!) le temps de réponse en fonction du taux d'arrivéelambda. Idéalement, vous devriez obtenir quelque chose du genre: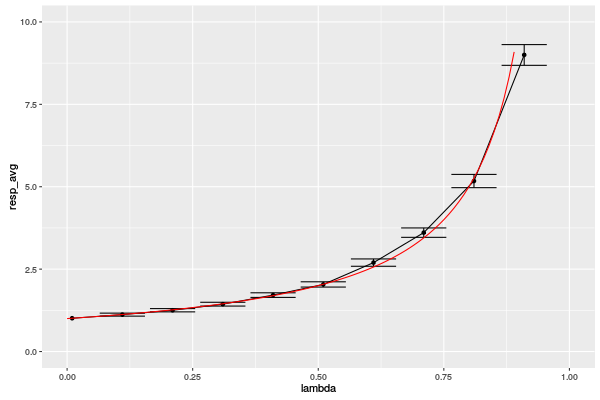
Calcul des valeurs propres et vecteurs propre de la bascule en R
library(expm) P = matrix(c(.75,.5,.25,.5),nrow=2) P X0 = matrix(c(0,1), nrow=1) X0 X0 %*% P X0 %*% P %*% P X0 %*% P %*% P %*% P X0 %*% P %*% P %*% P %*% P X0 %*% (P %^% 20)
[,1] [,2]
[1,] 0.75 0.25
[2,] 0.50 0.50
[,1] [,2]
[1,] 0 1
[,1] [,2]
[1,] 0.5 0.5
[,1] [,2]
[1,] 0.625 0.375
[,1] [,2]
[1,] 0.65625 0.34375
[,1] [,2]
[1,] 0.6640625 0.3359375
[,1] [,2]
[1,] 0.6666667 0.3333333
P %*% P P %^% 2 P %^% 4 P %^% 8 P %^% 10 P %^% 20
[,1] [,2]
[1,] 0.6875 0.3125
[2,] 0.6250 0.3750
[,1] [,2]
[1,] 0.6875 0.3125
[2,] 0.6250 0.3750
[,1] [,2]
[1,] 0.6679688 0.3320312
[2,] 0.6640625 0.3359375
[,1] [,2]
[1,] 0.6666718 0.3333282
[2,] 0.6666565 0.3333435
[,1] [,2]
[1,] 0.666667 0.333333
[2,] 0.666666 0.333334
[,1] [,2]
[1,] 0.6666667 0.3333333
[2,] 0.6666667 0.3333333
P EP = eigen(t(P)) EP SS = EP$vectors[,1] SS = SS/sum(SS) SS
Exercices pratiques sur les CMTD: Cache Web LRU + Move-Ahead
On dispose de \(N=100\) objets et on va étudier les performances d'un cache LRU de taille \(K\). Pour simplifier, on va supposer qu'un des objets est plus populaire (probabilité \(a\)) que les autres (probabilité \(b\)).
Modélisation faite en cours TD
Chaîne de Markov, calcul des probabilités stationnaires.
Compétence:
- Modélisation, exploitation de la symétrie du problème, égalité de passage d'un ensemble d'états à un autre
Simulation en R: Modélisation et Simulation d'un Cache Web
Extensions:
- Pour a et b fixé, à quoi ressemble la probabilité d'être bien servi en fonction de la taille du cache ? Pour LRU et Move-Ahead
- Discussion à propos de la signification de la deuxième valeur propre…
- Et s'il y a deux objets populaires, à quoi ressemble la chaîne de Markov ?
- En écho au récent keynote de James Roberts (Trading off memory for
bandwidth in a content-centric Internet).
- https://www.irt-systemx.fr/wp-content/uploads/2014/08/tradeoff-SX-noanim.pdf
- http://www.itc24.net/uploads/media/ITC24S2P4.pdf
- Refaire une simulation des deux lois en utilisant une loi de Zipf comme modèle de popularité.
Analyse des logs d'un serveur Web
Lecture des données
df = read.csv("logs/www.liglab.fr_access_log.2.dat",header=F) names(df) = c("IP","Date") head(df)
IP Date
1 46.4.69.163 01/Jan/2019:03:49:10 +0100
2 46.4.69.163 01/Jan/2019:03:49:10 +0100
3 46.4.69.163 01/Jan/2019:03:49:10 +0100
4 46.4.69.163 01/Jan/2019:03:49:10 +0100
5 46.229.168.132 01/Jan/2019:03:49:29 +0100
6 46.4.69.163 01/Jan/2019:03:49:36 +0100
Utilisation d'une librairie pour faire le parsing des dates.
library(lubridate) ymd_hms("2010-12-13 15:30:30"); # With Lubridate as.Date("2010-12-13 15:30:30",format="%y-%m-%d %h:%m:%s"); # With basic R functions
[1] "2010-12-13 15:30:30 UTC" [1] NA
library(lubridate)
df$Date = dmy_hms(df$Date)
str(df)
summary(df)
'data.frame': 386680 obs. of 2 variables:
$ IP : Factor w/ 7982 levels "1.10.186.180",..: 5718 5718 5718 5718 5681 5718 5718 5718 4684 5687 ...
$ Date: POSIXct, format: "2019-01-01 02:49:10" "2019-01-01 02:49:10" ...
IP Date
152.77.66.130: 28824 Min. :2019-01-01 02:49:10
152.77.66.134: 25735 1st Qu.:2019-01-07 12:49:40
152.77.66.142: 21570 Median :2019-01-11 14:10:15
152.77.66.138: 19812 Mean :2019-01-11 14:08:54
35.192.84.7 : 15865 3rd Qu.:2019-01-16 07:39:03
129.88.40.24 : 9997 Max. :2019-01-21 08:19:56
(Other) :264877
Première visualisation
plot(df) ; # Berk. This is completely useless!
C'est illisible et à la granularité de la seconde, ça n'a pas grand sens de toutes façons. Comptons combien de requêtes par minutes il peut y avoir pour avoir une idée de la charge.
df$Date_Minute = floor(as.numeric(df$Date)/60) head(df$Date_Minute)
[1] 25771849 25771849 25771849 25771849 25771849 25771849
library(dplyr) library(ggplot2) minTime = min(df$Date_Minute) df %>% group_by(Date_Minute) %>% summarise(count=n()) %>% ggplot(aes(x=Date_Minute, y=count)) + geom_point() + theme_bw() + xlim(minTime,minTime + 24*60)
Je me suis restraint à une partie des données mais si on regarde l'ensemble, on voit bien apparaître les jours de la semaine, les week-ends, la nuit, etc. Il y a une saisonalité et ça n'a pas de sens de faire des statistiques sur l'ensemble. Il faut se restreindre à une zone stable/stationnaire. Quand on ne distingue plus de structure, on peut alors considérer ces valeurs comme des variables aléatoires et les étudier comme telles. Évaluons la distribution sous-jacente à l'aide d'un histogramme.
minTime = min(df$Date_Minute) df_sel = df %>% group_by(Date_Minute) %>% summarise(count=n()) df_sel = df_sel[df_sel$Date_Minute >= minTime & df_sel$Date_Minute <= minTime + 24*60,] hist(df_sel$count,breaks=150)
Bon, par contre, quand on regarde à nouveau les données initiales, on s'apperçoit qu'il y a des "rafales". Ces rafales d'accès à la même heure par la même personne correspondent au fait qu'on trace au niveau apache et que la première requête en a déclanché d'autres (images, css, …). Mais ce qui nous intéresse, c'est les véritables requetes.
head(df)
IP Date Date_Hour Date_Minute
1 46.4.69.163 2019-01-01 02:49:10 25771849 25771849
2 46.4.69.163 2019-01-01 02:49:10 25771849 25771849
3 46.4.69.163 2019-01-01 02:49:10 25771849 25771849
4 46.4.69.163 2019-01-01 02:49:10 25771849 25771849
5 46.229.168.132 2019-01-01 02:49:29 25771849 25771849
6 46.4.69.163 2019-01-01 02:49:36 25771849 25771849
On peut les regrouper pour éliminer les doublons (à l'échelle de la minute, c'est raisonnable)
df_sel = df %>% group_by(Date_Minute,IP) %>% summarise(count=n()) %>% ungroup() %>% group_by(Date_Minute) %>% summarise(countIP=n()) minTime = min(df$Date_Minute) + 1640 df_sel = df_sel[df_sel$Date_Minute >= minTime & df_sel$Date_Minute <= minTime + 12*60,] plot(df_sel)
Et ça change singulièrement la distribution. C'est ça que nous allons chercher à modéliser.
hist(df_sel$countIP,breaks=25)
Bibliographie
- Fooling the masses by Georg Hager ;)
- Mor Harchol Balter - Performance Modeling and Design of Computer Systems: Queuing Theory in Action Cambridge University Press, 2013 http://www.cs.cmu.edu/~harchol/PerformanceModeling/book.html
- Un MOOC qui commence bientôt sur les files d'attente: https://www.edx.org/course/understanding-queues
- P. Brémaud, Initiation aux Probabilités
- R. Jain, The Art of Computer Systems Performance Analysis: Techniques for Experimental Design, Measurement, Simulation, and Modeling, Wiley- Interscience, New York, NY, April 1991.
- Jean-Yves Le Boudec, Performance Evaluation Of Computer And Communication Systems. Une jolie vidéo présentant le livre.