| EQUIPE
ASSOCIEE |
CloudShare |
|
sélection
|
2011 |
| Equipe-Projet INRIA : MESCAL | Organisme étranger partenaire : UC Berkeley (UCB) |
| Centre de recherche INRIA : Grenoble
Rhône-Alpes Thème INRIA : Num |
Pays : USA |
|
Coordinateur
français
|
Coordinateur
étranger
|
|
| Nom, prénom | Kondo, | Anderson, David P. |
| Grade/statut | CR2 INRIA | Research scientist, Director of BOINC & SETI@home |
| Organisme d'appartenance (précisez le département et/ou le laboratoire) |
MESCAL project team | U.C. Berkeley Space Sciences Laboratory |
| Adresse postale | Laboratoire LIG ENSIMAG - antenne de Montbonnot ZIRST 51, avenue Jean Kuntzmann 38330 MONBONNOT SAINT MARTIN, France |
7 Gauss Way Berkeley, CA 94720 |
| URL | http://mescal.imag.fr/membres/derrick.kondo/index.html | http://boinc.berkeley.edu/anderson |
| Téléphone | +33/0.4.76.61.20.61 | +1.510.642.4921 |
| Télécopie | +33/0.4.76.61.20.99 |
+1.510.643.7629 |
| Courriel | derrick.kondo@inria.fr | davea@ssl.berkeley.edu |
La proposition en bref
|
Titre de la thématique de collaboration (en français et en anglais) : Cloud Computing over Internet Volunteer Resources. Cloud computing sur ressources de calcul bénévoles. |
|
Descriptif: Recently, a new vision of cloud computing has emerged where the complexity of an IT infrastructure is completely hidden from its users. At the same time, cloud computing platforms provide massive scalability, 99.999% reliability, and speedy performance at relatively low costs for complex applications and services. In this proposed collaboration, we investigate the use of cloud computing for large-scale and demanding applications and services over the most unreliable but also most powerful resources in the world, namely volunteered resources over the Internet. The motivation is the immense collective power of volunteer resources (evident by FOLDING@home's 3.9 PetaFLOPS system), and the relatively low cost of using such resources. We will focus on three main challenges. First, we will determine, design and implement statistical and prediction methods for ensuring reliability, in particular, that a set of N resources are available for T time. Second, we will incorporate the notion of network distance among resources. Third, we will create a resource specification language so that applications can easily leverage these mechanisms for guaranteed availability and network proximity. We will address these challenges drawing on the experience of the BOINC team which designed and implemented BOINC (a middleware for volunteer computing that is the underlying infrastructure for SETI@home), and the MESCAL team which designed and implemented OAR (an industrial-strength resource management system that runs across France's main 5000-node Grid called Grid'5000). La notion de «cloud computing» apparue récemment a pour objectif de complètement masquer la complexité des infrastructures numériques actuelles à leurs utilisateurs. Ces plates-formes de cloud computing doivent donc massivement passer à l'échelle, être extrêmement fiables et fournir d'excellentes performances à faible coût aux applications et aux services qu'elles offrent. Dans le cadre de la collaboration que nous proposons, nous regarderons comment mettre en oeuvre cette idée de cloud computing pour des applications complexes et exigeantes sur les plates-formes les plus instables qui soient, mais également les plus puissantes: les ressources de calcul bénévole accessibles à partir d'Internet. La motivation derrière ce défi est l'incroyable puissance de calcul résultant de ces ressources (3.9 PetaFLOPS, rien que pour FOLDING@home) et leur très faible coût. Nous nous concentrerons sur trois axes principaux. Premièrement, nous chercherons à concevoir et à mettre en oeuvre des méthodes statistiques et de prédiction permettant d'améliorer la fiabilité de ces ressources. En particulier, nous nous intéresserons à la probabilité qu'un ensemble de N machines soit disponible durant une période de temps T. Deuxièmement, nous couplerons ces garanties de disponibilité de ressources avec des informations de proximité réseau entre les unes et les autres. Enfin, nous étendrons un langage de spécification de ressources classique afin que les applications et les services soient à même d'exprimer des besoins en terme de disponibilité et de proximité réseau. Nous relèverons ces défis en nous appuyant sur les expériences respectives des équipes impliquées: l'équipe BOINC a conçu et mis en oeuvre le middleware BOINC qui est utilisé à travers le monde entier et est est l'infrastructure sous-jacente à SETI@home; l'équipe MESCAL a conçu et mis en oeuvre OAR, un outil de gestion de ressources et de tâches de qualité industrielle et qui est notamment au coeur de Grid'5000. |
II. Key Results
Host Load Prediction in a Google Compute Cloud with a Bayesian Model
Partners: Walfredo Cirne (Google), Sheng Di (INRIA) , Derrick Kondo (INRIA)
Prediction of host load in Cloud systems is critical for achieving service-level agreements. However, accurate prediction of host load in Clouds is extremely challenging because it fluctuates drastically at small timescales. We have designed a prediction method based on Bayes model to predict the mean load over a long-term time interval, as well as the mean load in consecutive future time intervals. We have identified novel predictive features of host load that capture the expectation, predictability, trends and patterns of host load. We also have determineed the most effective combinations of these features for prediction. Our method was evaluated using a detailed one-month trace of a Google data center with thousands of machines. Experiments show that the Bayes method achieves high accuracy with a mean squared error of 0.0014. Moreover, the Bayes method improves the load prediction accuracy by 5.6-50% compared to other state-of-the-art methods based on moving averages, auto-regression, and/or noise filters.
This joint work was published at the IEEE/ACM Supercomputing Conference 2012.
Characterization and Comparison of Google Cloud Load versus Grids
Partners: Walfredo Cirne (Google), Sheng Di (INRIA) , Derrick Kondo (INRIA)
A new era of Cloud Computing has emerged, but the characteristics of Cloud load in data centers is not perfectly clear. Yet this characterization is critical for the design of novel Cloud job and resource management systems. In Cluster 2012, we comprehensively characterize the job/task load and host load in a real-world production data center at Google Inc. We use a detailed trace of over 25 million tasks across over 12,500 hosts. We study the differences between a Google data center and other Grid/HPC systems, from the perspective of both work load (w.r.t. jobs and tasks) and host load (w.r.t. machines). In particular, we study the job length, job submission frequency, and the resource utilization of jobs in the different systems, and also investigate valuable statistics of machine's maximum load, queue state and relative usage levels, with different job priorities and resource attributes. We find that the Google data center exhibits finer resource allocation with respect to CPU and memory than that of Grid/HPC systems. Google jobs are always submitted with much higher frequency and they are much shorter than Grid jobs. As such, Google host load exhibits higher variance and noise.This joint work was published at the IEEE Cluster Conference 2012.
A game theoretic point of view of Volunteer Computing
Partners: David Anderson (Berkeley), Arnaud Legrand (INRIA), Bruno Donassolo (INRIA)BOINC is the most popular VC infrastructure today with over 580,000 hosts that deliver over 2,300 TeraFLOP per day. BOINC projects usually have hundreds of thousands of independent tasks and are interested in overall throughput. Each project has its own server which is responsible for distributing work units to clients, recovering results and validating them. The BOINC scheduling algorithms are complex and have been used for many years now. Their efficiency and fairness have been assessed in the context of throughput oriented projects. Yet, recently, burst projects, with fewer tasks and interested in response time, have emerged. Many works have proposed new scheduling algorithms to optimize individual response time but their use may be problematic in presence of other projects. In CCGrid 2011, we have shows that the commonly used BOINC scheduling algorithms are unable to enforce fairness and project isolation in such a context. Burst projects may dramatically impact the performance of all other projects (burst or non-burst). To study such interactions, we have performed a detailed, multi-player and multi-objective game theoretic study. Our analysis and experiments provide a good understanding on the impact of the different scheduling parameters and show that the non-cooperative optimization may result in inefficient and unfair share of the resources.This work was published at the IEEE International Symposium on Cluster Computing and the Grid (CCGrid'12).
Predictive and Statistical Models of Volunteer Resource Availability
Partners: David Anderson (UCB), Jean-Marc Vincent (INRIA), Bahman Javadi (INRIA), Derrick Kondo (INRIA)During their visits to UCB and Geneva, Bahman Javadi, Derrick Kondo, and David Anderson discussed new methods for modelling resource availability of Internet hosts.
Invariably, volunteer platforms are composed of heterogeneous hosts whose individual availability often exhibit different statistical properties (for example stationary versus non-stationary behavior) and fit different models (for example Exponential, Weibull, or Pareto probability distributions). They developed an effective method for discovering subsets of hosts whose availability have similar statistical properties and can be modelled with similar probability distributions. They applied this method to ~230,000 host availability traces obtained SETI@home at UCB. The main contribution is the finding that hosts clustered by availability form 6 groups. These groups can be modelled by two probability distributions, namely the hyper-exponential and Gamma probability distributions. Both distributions are suitable for Markovian modelling. We believe that this characterization is fundamental in the design of stochastic algorithms for resource management across large-scale systems where host availability is uncertain.
This joint work was published at the MASCOTS 2009 conference and in the IEEE Transactions on Parallel and Distributed Systems 2011. This work is also connected to the constitution of the Failure Trace Archive whose presentation was done at CCGRID 2010
Cost-benefit Analysis of Volunteer versus Cloud Computing
Partners: David Anderson (UCB), Paul Malecot (INRIA), Bahman Javadi (INRIA), Derrick Kondo (INRIA)As the main goal of this project is to create a cloud computing platform using volunteer resources, we first studied the tradeoffs of a volunteer cloud platform versus a traditional cloud platform hosted on a dedicated data center. In particular, we studied the performance and monetary cost-benefits of two volunteer clouds (SETI@home and XtremLab) and a popular traditional cloud (Amazon's EC2, EBS, and S3). To conduct this study, David Anderson (UCB) provided the resource usage and volunteer statistics of SETI@home, a popular volunteer cloud hosted at UCB. Paul Malecot (INRIA) provided the resource usage and volunteer statistics of XtremLab, a volunteer cloud at INRIA. Together, David Anderson (UCB), Paul Malecot, Bahman Javadi, and Derrick Kondo (INRIA) determined the following:
- the performance trade-offs in using one platform over the other.
- the specific resource requirements and monetary costs of creating and deploying applications on each platform
- how traditional cloud platforms could be combined with volunteers to improve cost-effectiveness further
Combining Traditional Clouds with Volunteer Computing
Partners: David Anderson (UCB), Artur Andrzejak (ZIB), Derrick Kondo (INRIA)During his visit to UCB and China, Derrick Kondo discussed
with David Anderson ways in which traditional clouds could be
combined with volunteer resources. The cost-benefit
analysis in our first study showed that deploying
applications across a mixture of traditional cloud
resources and volunteer resources could lower costs even
further. The results of our second study gave us models
of availability that could be applied for improving the
reliability of volunteer resources. Thus, in this work,
we investigate the benefit for web services of using a
mixture of cloud and volunteer resources, leveraging our
predictive availability models.
We discuss an operational model which guarantees long-term
availability despite of host churn, and we study multiple
aspects necessary to implement it. These include: ranking of
non-dedicated hosts according to their long-term availability
behavior, short-term availability modeling of these hosts,
and simulation of migration and group availability levels
using real-world availability data from 10,000 non-dedicated
hosts participating in the SETI@home project provided by UCB.
We also study the tradeoff between a larger share of
dedicated hosts vs. higher migration rate in terms of costs
and SLA objectives. This yields an optimization approach
where a service provider can choose from a Pareto-optimal set
of operational modes to find a suitable balance between costs
and service quality. The experimental results show that it is
possible to achieve a wide spectrum of such modes, ranging
from 3.6 USD/hour to 5 USD/hour for a group of at least 50
hosts available with probability greater than 0.90.
This joint work was published at the NOMS 2010 conference.
With respect to idle data centers, Amazon Inc. is currently selling the idle resources of their data centers using Spot Instances. With the recent introduction of Spot Instances in the Amazon Elastic Compute Cloud (EC2), users can bid for resources and thus control the balance of reliability versus monetary costs. A critical challenge is to determine bid prices that minimize monetary costs for a user while meeting Service Level Agreement (SLA) constraints (for example, sufficient resource availability to complete a computation within a desired deadline). We propose a probabilistic model for the optimization of monetary costs, performance, and reliability, given user and application requirements and dynamic conditions. Using real instance price traces and workload models, we evaluate our model and demonstrate how users should bid optimally on Spot Instances to reach different objectives with desired levels of confidence. To harness idle resources on the Amazon Cloud via BOINC, we have successfully deployed a BOINC client and server in Amazon's cloud and are working on further integration.This was work published at the 18th IEEE/ACM International Symposium on Modeling,
Analysis and Simulation of Computer and Telecommunication
Systems (MASCOTS), September, 2010
and the 3rd International Conference on
Cloud Computing (IEEE CLOUD 2010), July, 2010.
Automated Generation of Virtual Machine Images
Partners: David Anderson (UCB), Yiannis Georgiou (INRIA), Bruno Bzeznik (INRIA), Joseph Emeras (INRIA), Darko Ilic (INRIA), Olivier Richard (INRIA)One sub-goal of Research Thrust #1 was the incorporation of virtual machines in BOINC. A major issue in this incorporation is the configuration of the virtual machine, in particular the image, itself. Scientists should be able to easily customize a virtual image of the operating system, and required libraries and applications. This image can then be deployed across a distributed computing environment, such as BOINC or Grid'5000. Y. Geogiou et al. have implemented a virtualization tool called Kameleon that enables such customization of the virtual image. This tool takes as input the image specification and description. The specification describes various parameters such as the OS distribution (for example, debian lenny, centos 5), kernel, packages/libraries (OpenMPI, MPICH), benchmarks (LINPACK, NAS), and output image format (ISO, COS, TGZ). The description details what actions to take using those parameters in macrosteps and microsteps. Examples of macrosteps are initializing the module repository, and configuring the package manager. Examples of microsteps are checking the command error code, executing a bash script on the host system, or writing to a file of the image. The Kameleon Engine was implemented in Ruby. The configuration files are specified using YAML, which is a markup language designed to be easily mapped to data structures such as lists, hashes, and scalars.
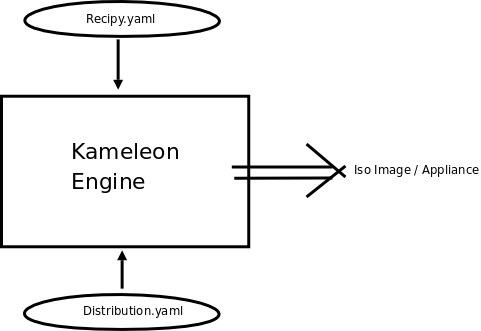
The tool was intentionally designed to be
generic, and applicable to any system, such as Grid'5000 or
BOINC, that uses virtualization. The next step will be
to integrate the tool with virtualization in BOINC.
Internet-Wide Distributed Computing With OAR and BOINC
Partners: David Anderson (UCB), Thiago Presa (INRIA), Bruno Bzeznik (INRIA), Derrick Kondo (INRIA), Olivier Richard (INRIA)OAR is the current production batch scheduler
of Grid'5000. However, it was not originally designed
for using Internet volunteer computing resources. In
particular, volunteer computing resources must use HTTP to
communicate with the OAR server, and pull (versus push) jobs
from the server to bypass firewalls. We made
significant changes to the OAR server API such that an
desktop agent can get jobs (executable, inputs), post the job
state, post results, and kill jobs from the OAR server all
through a REST architecture. The REST (short for
Representational State Transfer) architecture is advantageous
because it inherently allows for scalable component
interactions and provides a general interface. We
implemented a desktop agent that applies that API to
retrieve, execute, and return jobs.
The OAR desktop agent will fit in the
CloudShare deployment as follows. A virtual machine
image will have the desktop agent pre-installed and configure
to start and execute on system boot-up. This virtual
machine (VM) image will be deployed and controlled by the
BOINC client, running on desktop volunteers. Once the
VM image is deployed and booted-up, the desktop agent will
execute, and pull and execute jobs from the OAR server using
the REST API. The BOINC server will essentially only be
used to deploy the virtual machine, and all interaction with
jobs will between the desktop agent and OAR, bypassing the
BOINC server completely. The design choice was made to
prevent issues of synchronization between the OAR and BOINC
servers, in terms of job and host tables.
The source code for the REST API of OAR and
the desktop agent is
available.
Deploying Real-Time Services over Unreliable, Shared BOINC Resources
Partners: David Anderson (UCB), Derrick Kondo (INRIA), Sangho Yi (INRIA)At the joint
meeting among David Anderson, Derrick Kondo, and Sangho Yi at
UC Berkeley, they discussed ways to improve BOINC so that it
can support demanding real-time applications in the
CloudShare system.
One major challenge is the server-side management of these tasks, which often number in tens or hundreds of thousands on a centralized server. In the work described in Euro-Par 2010, we design and implement a real-time task management system for many-task computing, called RT-BOINC. The system gives low O(1) worst-case execution time for task management operations, such as task scheduling, state transitioning, and validation. We implemented this system on top of BOINC. Using micro and macro-benchmarks executed in emulation experiments, we showed that RT-BOINC provides significantly lower worst-case execution time, and lessens the gap between the average and the worst-case performance compared with the original BOINC implementation.
The joint work was published in European Conference on Parallel and Distributed
Computing (Euro-Par) in 2010.
Simulation of Volunteer Computing Platforms
Partners: David Anderson (UCB), Arnaud Legrand (INRIA), Bruno Donassolo (INRIA), Pedro Velho (INRIA)During his visit to UC Berkeley, Arnaud
Legrand discussed with David Anderson the issue of
large-scale volunteer computing simulation and its
visualization and analysis.
To evaluate different policies for
fault-tolerance achieved via virtual machines, we need a
volunteer computing (VC) simulator to allow for reproducible
and configurable experiments. The main issue when
developing VC simulators is scalability: How to perform
simulations of large-scale VC platforms with reasonable
amounts of memory and reasonably fast? To achieve
scalability, state-of-the-art VC simulators employ simplistic
simulation models and/or target on narrow platform and
application scenarios. In this work, we enable VC simulations
using the general-purpose SimGrid simulation framework, which
provides significantly more realistic and flexible simulation
capabilities than the aforementioned simulators. The key
contribution is a set of improvements to SimGrid so that it
brings these benefits to VC simulations while achieving good
scalability.
The scalability of simulations was evaluated
using traces collected of SETI@home collected by the BOINC
team. Also, the simulator developed used a simulation
model of the BOINC client, which uses several complex
policies for dealing with host failures, application
deadlines, and user constraints.
Later on, we extended SimGrid to seamlessly handle arbitrarily complex network topologies in a scalalable way. Such techniques allows to simulate not only CPU bound VC systems but also network bound VC projects. More importantly, this kind of flexibility allows to study the interactions of grids or cloud systems with VC systems and of how they could build on top of each others. The description of the used techniques and data structures was done in CCGRID 2011 and incorporated in the SimGrid stable version in 2011. Such approach enable us to efficiently simulate systems with up to million of process in a quite detailed way, hence accounting for many non trivial phenomena. Building on the workload characterization of availability traces with stochastic laws, we have started implementing such generative models directly into SimGrid. This obviously avoids loading a very large amount of traces as an input to the simulator and to generate such events on the fly. Beside the efficiency and better scalability of such approach, it allow to study much more easily the sensitivity of simulation results to workload parameters, which is crucial when performing simulation based studies.
Large-scale Volunteer Computing Trace Visualization
Partners: David Anderson (UCB), Arnaud Legrand (INRIA), Lucas Schnorr (INRIA), Jean-Marc Vincent (INRIA)The previous work enabled large-scale simulation of a system with 10,000+ nodes. After simulations are run, another critical challenge arises, namely an understanding of the massive simulation execution traces and results. One approach is to use visualization techniques to understand system bottlenecks and anomalies. However, current visualization tools are not able to scale to 10,000 nodes. To address this issue, we developed the Triva visualization tool to help understand the simulated execution of large-scale application and systems. This tool allows for slow-motion playback of application execution, temporal integration using dynamic time intervals, spatial aggregation through hierarchical traces, scalable visual analysis with Squarified Treemaps, and a custom graph visualization.As a case study, we applied Triva to a large-scale simulation of BOINC system involving 10,000+ nodes. We used Triva successfully and scalably to visualize the state of nodes in the system, in particular their current workload and availability. We also used Triva to identify major network bottlenecks, which would otherwise have been impossible without visualization techniques.
This work was published in LSAP 2010 and in Concurrency
and Computation: Practice and Experience, 2011 and
in.
Visits and events
2013
- The annual BOINC workshop was organized in Grenoble. This event gathered around 30 researchers relying or working on BOINC. This event was a success and also attracted attendees from Grenoble. This year, the workshop did last for three days. The first day was devoted to presentations of activities and plans related to volunteer computing. On the 2nd and 3rd days of the workshop participants did divide into groups, to hack, improve, document, discuss or learn some aspect of BOINC.
- Arnaud Legrand (MESCAL researcher) went for a week in May to Berkeley to work with David Anderson. He also presented the associated team to the BIS (Berkeley/Inria/Stanford) workhop.
- Unfortunately, both Bruno Gaujal (MESCAL researcher) and Rhonda Righter (Berkeley) had to cancel their visits for personnal reasons.
2012
- Sheng Di (MESCAL post-doc with Derrick Kondo) went in November at UCB to visit David Anderson and at Google to visit Walfredo Cirne.
- Arnaud Legrand (MESCAL researcher) went in September to the annual BOINC workshop in London, where he met David Anderson and the BOINC community.
- Bruno Gaujal (MESCAL researcher) went to Berkeley in December to visit Rhonda Righter (Berkeley).
2011
- Arnaud Legrand (MESCAL researcher) and Slim Bouguerra (MESCAL post-doc) went for a week in May to visit David Anderson at Berkeley.
- Arnaud Legrand (MESCAL researcher) went in August to the annual BOINC workshop in Hannover, where he met David Anderson and the BOINC community.
- Missing information to complete...
2010
- Arnaud Legrand (MESCAL researcher) went for a week in May to visit David Anderson at Berkeley. He also visited Walfredo Cirne at Google.
- Derrick Kondo (MESCAL researcher) went in September to the annual BOINC workshop in London.
- Bruno Donnassolo (MESCAL master student) went at Chicago (LSAP 2010) to present his work.
- Missing information to complete...
2009
- Bruno Donassolo (MESCAL master) and Pedro Velho (MESCAL PhD) went in October to the annual BOINC workshop in Barcelona.
- Missing information to complete...
Software
OAR desktop agent and REST server APIKameleon configuration engine for Virtual Machine images.
SimGrid with new functionality for supporting simulation of large scale volunteer computing environments (lazy update mechanism, trace integration, hierarchical platform representation, dynamic trace generation from stochastic description). Note that the SimGrid project was started about 10 years ago, but these new functionalities were introduced only recently.
A full-fledge simulator of BOINC using SimGrid is now hosted on the SimGrid website.
Triva visualization tool for large-scale trace analysis. Demo of Triva applied to the SETI@home/BOINC availability traces and volunteer computing simulation.
RT-BOINC is a real-time version of the BOINC server. It was designed for managing highly-interactive, short-term, and massively-parallel real-time applications. RT-BOINC was designed and implemented on top of BOINC server source codes.
PhD Thesis and Masters
- Bruno Donassollo has received his Master from University Federale Rio Grande do Sul (Porto Alegre, Brazil) in 2011. He worked in the MESCAL team for 6 months as an INRIA intern. He developped SimGrid in LSAP 2010 to enable scalable simulations of VC systems as well as a full-fledge simulation of BOINC based on SimGrid, which was latter used in CCGrid 2012 to study BOINC with a game-theoretic perspective.
- Duco Van Amstel has received his Master from ENS Lyon in 2012. He worked in the MESCAL team for 4 months as an intern on scheduling strategies for umbrella projects interested in response time optimization rather than throughput optimization.
Publications
2014
Journal
- Sheng Di, Derrick Kondo, Walfredo Cirne. Google hostload prediction based on Bayesian model with optimized feature combination. J. Parallel Distrib. Comput. 74(1), 2014
2013
Journal
- Bahman Javadi, Derrick Kondo, Alexandru Iosup, Dick H. J. Epema. The Failure Trace Archive: Enabling the comparison of failure measurements and models of distributed systems. J. Parallel Distrib. Comput. 73(8), 2013
In Proceedings
- Sheng Di, Derrick Kondo, Franck Cappello. Characterizing Cloud Applications on a Google Data Center. ICPP 2013
2012
Journal
- Eric Heien, Derrick Kondo, David P. Anderson. A Correlated Resource Model of Internet End Hosts. IEEE Transactions on Parallel and Distributed Systems, 2012
In Proceedings
- Sheng Di, Derrick Kondo, Walfredo Cirne. Characterization and Comparison of Google Cloud Workload versus Grids. Proceedings of the IEEE Cluster Conference, 2012.
- Sheng Di, Derrick Kondo, Walfredo Cirne. Host Load Prediction in a Google Compute Cloud with a Bayesian Model. IEEE/ACM Supercomputing Conference (SC), nov 2012.
- Laurent Bobelin, Arnaud Legrand, David Alejandro Gonzà lez Mà rquez, Pierre Navarro, Martin Quinson, Frédéric Suter, Christophe Thiery. Scalable Multi-Purpose Network Representation for Large Scale Distributed System Simulation. Proceedings of the 12th IEEE International Symposium on Cluster Computing and the Grid (CCGrid'12), may 2012.
2011
Article
- Bahman Javadi, Derrick Kondo, Jean-Marc Vincent, David P. Anderson. Discovering Statistical Models of Availability in Large Distributed Systems: An Empirical Study of SETI@home. IEEE Transactions on Parallel and Distributed Systems, 22(11):1896-1903, Nov 2011.
- Sangho Yi, Artur Andrzejak, Derrick Kondo. Monetary Cost-Aware Checkpointing and Migration on Amazon Cloud Spot Instances. IEEE Transactions on Services Computing, 2011.
- Lucas Mello Schnorr, Arnaud Legrand, Jean-Marc Vincent. Detection and analysis of resource usage anomalies in large distributed systems through multi-scale visualization. Concurrency and Computation: Practice and Experience, 2011.
In Proceedings
- Eric Heien, Derrick Kondo, Ana Gainaru, Dan LaPine, Bill Kramer, Franck Cappello. Modeling and Tolerating Heterogeneous Failures on Large Parallel Systems. IEEE/ACM Supercomputing Conference (SC), nov 2011.
- Eric Heien, Derrick Kondo, David P. Anderson. Correlated Resource Models of Internet End Hosts. The 31st IEEE International Conference on Distributed Computing Systems (ICDCS'11), jun 2011.
- Sangho Yi, Emmanuel Jeannot, Derrick Kondo, David P. Anderson. Towards Real-Time Volunteer Distributed Computing. 11th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing (CCGrid 2011), may 2011.
- Bruno De Moura Donassolo, Arnaud Legrand, Claudio Geyer. Non-Cooperative Scheduling Considered Harmful in Collaborative Volunteer Computing Environments. Proceedings of the 11th IEEE International Symposium on Cluster Computing and the Grid (CCGrid'11), may 2011.
- Lucas Mello Schnorr, Arnaud Legrand, Jean-Marc Vincent. Multi-scale analysis of large distributed computing systems. Proceedings of the third international workshop on Large-scale system and application performance (LSAP'11), 2011.
2010
In Proceedings
- Derrick Kondo, Bahman Javadi, Alexandru Iosup, Dick H. J. Epema. The Failure Trace Archive: Enabling Comparative Analysis of Failures in Diverse Distributed Systems. Proceedings of the IEEE International Symposium on Cluster Computing and the Grid (CCGRID), 2010.
- Sangho Yi, Derrick Kondo, David P. Anderson. Toward Real-Time, Many-Task Applications on Large Distributed Systems. European Conference on Parallel and Distributed Computing Euro-Par, 2010.
- Sangho Yi, Derrick Kondo, Bongjae Kim, Geunyoung Park, Yookun Cho. Using replication and checkpointing for reliable task management in computational Grids. IEEE International Conference on High Performance Computing & Simulation HPCS), 2010.
- Artur Andrzejak, Derrick Kondo, David P. Anderson. Exploiting non-dedicated resources for cloud computing. IEEE/IFIP Network Operations and Management Symposium (NOMS), 2010.
- Sangho Yi, Derrick Kondo, Artur Andrzejak. Reducing Costs of Spot Instances via Checkpointing in the Amazon Elastic Compute Cloud. 3rd Conference on Cloud Computing, IEEE CLOUD, jul 2010.
- Bruno De Moura Donassolo, Henri Casanova, Arnaud Legrand, Pedro Velho. Fast and Scalable Simulation of Volunteer Computing Systems Using SimGrid. Workshop on Large-Scale System and Application Performance (LSAP), 2010.
2009
In Proceedings
- Derrick Kondo, Bahman Javadi, Paul Malécot, Franck Cappello, David P. Anderson. Cost-Benefit Analysis of Cloud Computing versus Desktop Grids. 18th International Heterogeneity in Computing Workshop may 2009.
- Bahman Javadi, Derrick Kondo, Jean-Marc Vincent, David P. Anderson. Mining for Statistical Models of Availability in Large-Scale Distributed Systems: An Empirical Study of SETI@home. 17th IEEE/ACM International Symposium on Modelling, Analysis and Simulation of Computer and Telecommunication Systems (MASCOTS), sep 2009.