RICM4: Évaluation de Performance
Table of Contents
Sitemap
|
|




Informations Générales
Florence Perronnin est chargée des cours et Arnaud Legrand s'occupe des TDs.
Le planning avec les salles de cours est disponible ici.
La page de l'an dernier est ici.
Voici un PAD pour échanger facilement et rapidement des informations.
Programme du cours
| Semaine | Cours (Jeudi, 8h00) | TD (Vendredi, 11:30 ou exceptionnellement 8:00) |
|---|---|---|
| 18-19 janvier | Slides d'introduction + Modélisation des files d'attente | Simulation à évènement discret d'une M/M/1 |
| 25-26 janvier | Modélisation des files d'attente et des systèmes Markoviens | Pas de TD |
| 1-2 février | Chaînes de Markov à Temps Discret | Simulation à évènement discret d'une M/M/1 |
| 8-9 février | Chaînes de Markov à Temps Discret | Présentation du DM et exercice 2 d'un Quick de l'an dernier (chocolats) |
| 15-16 février | Processus de Poisson | Quick de l'an dernier |
| 22-23 février | Vacances | Vacances |
| 1-2 mars | Processus de Poisson | Aloha! |
| 8-9 mars | Quick | Aloha! |
| 15-16 mars | Chaîne de Markov à temps continu | Discussions sur le DM + Cache-cache (correction et code R) |
| 22-23 mars | Processus de naissance et de mort, file M/M/1 | TD sur les iles d'attente. En bonus, un aide mémoire sur la M/M/1 et sur la M/M/K/K. |
| 29-30 mars | Régression linéaire (Arnaud) | Réseaux de Jackson (Florence) |
| 3 avril | La régression linéaire en pratique + open questions (Arnaud: le 3 avril à 10h00) |
DM/Projet
Énoncé
Simuler, analyser et comparer les politiques d'au moins trois des files d'attentes suivantes:
- Fair sharing
- à chaque instant \(t\), si on note \(M_t\) le nombre de tâches actuellement présentes sur le serveur. Toutes les tâches soumises et non terminées s'exécutent en parallèle sur le serveur et avancent donc à une vitesse \(1/M_t\) jusqu'à ce qu'une tâche se termine ou qu'une tâche supplémentaire soit soumise dans le système.
- FIFO
- déjà faite en TD…
- LIFO
- Lorsqu'une tâche se termine, la tâche que l'on exécute est la dernière arrivée.
- LIFO avec préemption
- Lorsqu'une tâche arrive dans le système, on préempte la tâche qui s'exécutait pour exécuter la nouvelle tâche. Cette nouvelle tâche peut se faire préempter à son tour si une nouvelle tâche arrive, etc. Lorsque la nouvelle tâche se termine, on reprend la dernière tâche interrompue là où on l'avait arrêtée.
- LIFO avec restart
- Même principe que LIFO avec préemption, à ceci près qu'on recommence la dernière tâche interrompue du début, comme si elle n'avait jamais été exécutée, en retirant nouveau un temps de service.
- SPT
- Shortest Processing Time first. Lorsqu'une tâche se termine, on exécute non pas la première ou la dernière tâche arrivée mais celle ayant le plus petit temps de traitement.
- SRPT
- Shortest Processing Time first. Lorsqu'une tâche se termine ou qu'une nouvelle tâche arrive, on exécute la tâche pour lequel il reste le moins de travail à effectuer.
On supposera que les arrivées suivent une loi exponentielle de taux \(\lambda\) et que les temps de service sont d'espérance 1. Vous comparerez les performances (en fonction de \(\lambda\)) des trois politiques selon que le temps de service suit une loi:
- uniforme entre 0.5 et 1.5
- exponentielle de taux 1
gammade paramètreshape=.1etrate=.1
Vous vérifierez l'espérance et la variance de vos échantillons…
Je vous encourage à avoir une seule fonction de simulation pour l'ensemble des scénarios considérés.
Objectifs pédagogiques
Savoir:
- savoir collecter et organiser les données d'un grand nombre de
simulations (
data.frame) - savoir calculer des intervalles de confiance (avec
tidyretdplyr) - savoir faire une représentation graphique adaptée (avec
ggplot2)
Avoir compris:
- la notion d'état du système et comment on le met à jour
- la notion de stabilité d'un système
- la limite de la notion d'intervalle de confiance
Consignes
- Rendu en Rmd sur rpubs pour le 16 mars
- À faire en binôme. Chaque binôme choisi ses trois politiques dans la
liste suivante. Un triplet ne peut être pris que par un binôme afin
de s'assurer que toutes les politiques sont codées et qu'on puisse
vérifier qu'elles sont correctement implémentées en faisant des
validations croisées. Premier servi, à indiquer sur le PAD:
- FIFO, SPT, LIFO-preemption
- FIFO, LIFO, SPT
- FIFO, Fair-sharing, LIFO
- FIFO, LIFO-preemption, SRPT
- FIFO, LIFO-restart, Fair-sharing
- FIFO, SRPT, LIFO-restart
- Vous vous mettrez tous d'accord sur le format de data-frames utilisées afin de sauvegarder les résultats des simulations (et vous les mettrez à disposition (dans un git, framadrop, ou autre). Ça permettra de charger les résultats de différents binômes pour les comparer.
- Partage d'information encouragé mais:
- faites en sorte que ça soit réciproque
- indiquez brièvement à la fin du document avec qui vous avez échangé et sur quoi
- Une séance de TD sera dédié à une brève présentation de vos résultats en vous appuyant sur ce qui est dans Rpubs.
Commentaires
Pour tout le monde: le geom_smooth n'a pas de sens donc ne l'utilisez
pas.
- FOMBARON Quentin - BESNARD Guillaume
- FIFO / LIFO-restart /
Fair-sharing http://rpubs.com/gbesnard/369625 A-
- Le code (simulation, intervalles de confiances, plyr et ggplot, …) est bien. C'est une bonne idée d'avoir fait une visu de l'exécution des tâches au cours du temps pour mieux comprendre ce qu'il se passait.
- Pour les courbes de temps de réponse, où vous auriez dû limiter l'axe des y à (0,10) car ça n'a plus grand sens au delà et permet de mieux voir ce qu'il se passe pour les petites valeurs de lambda.
- Comme vous avez 9 courbes de temps de réponse indépendantes, la comparaison est difficile.
- Il n'y a pas un seul commentaire! Vous savez depuis le temps pourtant que c'est justement ce qui m'intéresse.
- LEVESQUE Théo - JEAN Jordan
- FIFO / Fair-sharing / LIFO
http://rpubs.com/theo024/ricm4-ep-dm-jean-levesque A
- Le code (simulation, intervalles de confiances, plyr et ggplot, …) est bien. RAS.
- Pour les courbes de temps de réponse, où vous auriez dû limiter l'axe des y à (0,10) car ça n'a plus grand sens au delà et permet de mieux voir ce qu'il se passe pour les petites valeurs de lambda.
- Vous avez sauvegardé les résultats des simulations plutôt que de les refaire à chaque fois. C'est bien.
- Petite remarque. Vous réécrivez à chaque fois
%>% group_by(lambda) [...] geom_smooth(). Vous pourriez en faire une fonction. C'est compatible avec l'opérateur +. - Comme vous avez 9 courbes de temps de réponse indépendantes, la
comparaison est difficile.
- Du coup, quand vous commentez, " Concernant la politique Fair Sharing on obtient un temps de réponse moyen plus grand de 2 unités en moyenne lorsque lambda est supérieur à 0.75.", j'ai beau chercher, je n'arrive pas à le voir dans vos courbes.
- Pour ce qui est de l'incertitude qui augmenterai plus our LIFO/exp que pour FIFO/exp, c'est un coup de malchance a priori. Répéter l'expérience avec une graine différente ou avec un N plus grand devrait faire disparaître le phénomène.
- En fait, la bonne façon de faire, c'est de faire une première série de simulation, d'émettre des hypothèses et de refaire d'autres simulations pour les vérifier…
- DEPRIESTER Timothée - Thibaud Vegreville
- FIFO / LIFO-préemption /
SRPT http://rpubs.com/Thibaud/369974 A-
- Le code est pas mal et vous citez vos sources (merci!) mais vous avez visiblement une erreur dans l'implémentation de LIFO. Un temps de réponse moyen de 0 quand lambda est proche de 0, vous avez pris ça pour une bonne propriété de cette politique mais ça n'est tout simplement pas possible. Je ne sais pas où est l'erreur, elle ne m'a pas sauté aux yeux en lisant votre code.
- Votre calcul de l'intervalle de confiance est fait avant le
group_by, donc sur l'ensemble des données et n'a du coup pas de sens. D'autre part, unt.testn'a aucun intérêt ici. Utilisez plutôt la formule du théorème central limite. - Comme vous avez 9 courbes de temps de réponse indépendantes, la
comparaison est difficile.
- Ceci dit, SRPT est effectivement optimale
- GENTILLON Loris - SURIER Aurélien
- FIFO / SPT/ LIFO-préemption
http://rpubs.com/AurelienSurier/370172 C
- Il y a comme un problème avec votre fonction
trace_completion_time, vous auriez du limiter aux premières tâches car c'est effectivement illisible là. Ah, et j'ai mis un certain temps avant de réaliser que vous mettiez sur le même graphe les données de tâches correspondant à des simulations (des lambda) différentes. - Les graphes pour FIFO sont OK.
- Le code de sélection de la CurrentTask pour SPT, c'est n'importe quoi… Vous ne regardez même pas le processing time pour faire votre sélection. Au final, ça revient à FIFO.
- Les graphes pour SPT du coup ressemblent à ceux pour FIFO, sauf par "malchance" ou quand vous changez les paramètres (N en particulier pour gamma).
- L'implémentation de LIFO-pmtn est également complètement fausse. Je n'arrive même pas à comprendre ce que vous essayez de faire. Désolé…
- Il y a comme un problème avec votre fonction
- CHARLOT Servan - CHANET Zoran
- FIFO / SRPT / LIFO-restart
http://rpubs.com/Servan42/EPDM A+
- Le code est bon, sépare bien génération de données et analyses.
- Vous êtes finalement les seuls à m'avoir rendu 2 graphiques et pas 9. Je sais que ça vous a pris du temps, mais ça permet vraiment de mieux comparer les situations.
- Vous auriez pu rajouter vos intervalles de confiance, sur ces graphes facettés. Surtout que vous m'écrivez "Sur les graph ci-dessus, il est compliqué d’analyser les intervalles de confiance". C'est dommage mais pas bien grave.
- BELGUENDOUZ Sekina - EZ-ZINE Najwa
- FIFO / LIFO / SPT
http://www.rpubs.com/belguens/370449 A
- OK pour les conclusions sur les politiques et sur les lois de service.
- "Gamma semble être encore plus incompatible avec LIFO qu’avec FIFO". Non, pas vraiment. Vous ne prenez pas en compte l'incertitude (intervalles de confiance) dans vos estimations pour conclure.
TDs
Simulation à évènement discrets de file d'attentes
L'objectif du TD est de comprendre la bonne façon d'organiser une simulation à évènement discret (sans reposer trop intensément sur les hypothèse type arrivées de Poisson) avec la notion d'état du système, d'évènements possible et de mise à jour de l'état du système. Si vous lisiez des bouquins qui expliquent comment faire de la simulation à évènement discret, il n'est pas clair que ça vous aiderait vraiment. Le mieux est d'en écrire un ensemble pour que vous compreniez comment procéder. Pour celà, on va s'intéresser au cas simple d'une file d'attente.
Modélisation et principe de simulation
- Paramètres du système
- Taux d'arrivée dans le système
lambda(en tâches par seconde) - Taux de service du système
mu(en tâches par seconde) - Politique de service (on va coder FIFO là mais on essaye de coder tout ça de la façon la plus générique possible)
- Taux d'arrivée dans le système
Description des variables d'état importantes:
- Date courante
t - Dates d'arrivées
Arrival: dates calculées à partir d'inter-arrivées (input) - Temps de service
Service: temps générés (input) - Temps résiduel
Remaining: initialisé àNA, passe à Service quand un job arrive dans le système et décroit alors vers 0. - Date de terminaison
Completion: initialisé àNA, passe à la date courantetlorsqueRemainingpasse à 0. - Client actuellement servi
CurrClient(utile pour caractériser la politique de service utilisée): initialisé àNA
J'ai finalement rajouté une variable
NextArrivalqui permet d'éviter des contortions ou des notations un peu lourdes. Cette variable est initialisée à1et sera incrémentée jusqu'à dépasser le nombre de tâches total.- Date courante
- Évolution possible
- Soit une arrivée
- Soit la terminaison d'une tâche
Structure du code:
while(T) { dtA = ... # temps jusqu'à la prochaine arrivée dtC = ... # temps jusqu'à la prochaine terminaison if(is.na(dtA) & is.na(dtC)) {break;} dt = min(dtA,dtC) # Mettre à jour comme il faut. }
Première version faite en TD
set.seed(37); N = 10; # N <- 100; # N <<- 100; Arrival = cumsum(rexp(n=N, rate = .2)); Service = rep(N,x=1); Remaining = rep(N, x=NA); Completion = rep(N, x=NA); t = 0; CurrentTask = NA; NextArrival = 1; while (TRUE) { print(t); print(Arrival); print(Service); print(Remaining); dtA = NA; dtC = NA; if(length(Arrival[Arrival>t])>0) { dtA = head(Arrival[Arrival>t],n=1)-t # temps jusqu'à la prochaine arrivée } if(!is.na(CurrentTask)) { dtC = Remaining[CurrentTask]; # temps jusqu'à la prochaine terminaison } if(is.na(dtA) & is.na(dtC)) { break; } dt = min(dtA,dtC,na.rm=T) # Mettre à jour comme il faut: # la date t = t + dt; # les arrivées if((NextArrival <=N) & (Arrival[NextArrival] <= t)) { ## je met un <= et pas un == car 3-2.9!=0.1 ... Remaining[NextArrival] = Service[NextArrival]; NextArrival = NextArrival + 1; } # le remaining if(!is.na(CurrentTask)) { Remaining[CurrentTask] = Remaining[CurrentTask] - dt ; if(Remaining[CurrentTask] <= 0) { Completion[CurrentTask] = t; Remaining[CurrentTask] = NA; } CurrentTask = NA; } # et currentTask (politique d'ordonnancement: FIFO) WaitingList=(1:N)[!is.na(Remaining)]; if(length(WaitingList)>0) { CurrentTask = head(WaitingList,n=1); } } print(Completion)
Pour la prochaine fois:
- Repartir de votre propre version (si vous voulez bien comprendre comment ça marche) ou à défaut de celle donnée ci dessous (si vous renoncez à écrire ce code vous-même proprement…) et l'encapsuler de façon à pouvoir facilement controler les paramètres du système (lambda, mu)
Fixer le taux de service
muà 1 et étudier (je veux une courbe!) le temps de réponse en fonction du taux d'arrivéelambda. Idéalement, vous devriez obtenir quelque chose du genre: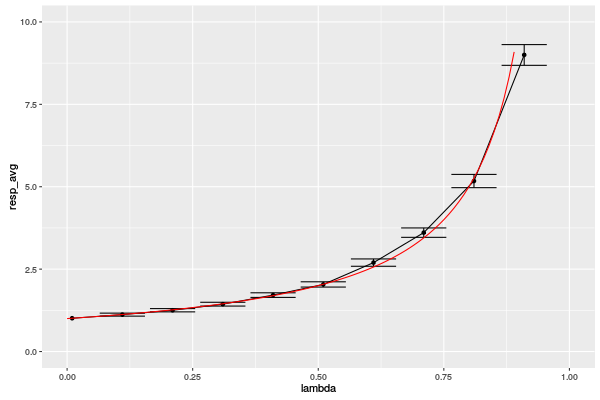
Bibliographie
- Fooling the masses by Georg Hager ;)
- Mor Harchol Balter - Performance Modeling and Design of Computer Systems: Queuing Theory in Action Cambridge University Press, 2013 http://www.cs.cmu.edu/~harchol/PerformanceModeling/book.html
- Un MOOC qui commence bientôt sur les files d'attente: https://www.edx.org/course/understanding-queues
- P. Brémaud, Initiation aux Probabilités
- R. Jain, The Art of Computer Systems Performance Analysis: Techniques for Experimental Design, Measurement, Simulation, and Modeling, Wiley- Interscience, New York, NY, April 1991.
- Jean-Yves Le Boudec, Performance Evaluation Of Computer And Communication Systems. Une jolie vidéo présentant le livre.